|
Объектно-ориентированная технология основывается на так называемой объектной модели. Основными ее принципами являются: абстрагирование, инкапсуляция, модульность, иерархичность, типизация, параллелизм и сохраняемость. Каждый из этих принципов сам по себе не нов, но в объектной модели они впервые применены в совокупности.
Объектно-ориентированный анализ и проектирование принципиально отличаются от традиционных подходов структурного проектирования: здесь нужно по-другому представлять себе процесс декомпозиции, а архитектура получающегося программного продукта в значительной степени выходит за рамки представлений, традиционных для структурного программирования. Отличия обусловлены тем, что структурное проектирование основано на структурном программировании, тогда как в основе объектно-ориентированного проектирования лежит методология объектно-ориентированного программирования, К сожалению, для разных людей термин "объектно-ориентированное программирование" означает разное. Ренч правильно предсказал: "В 1980-х годах объектно-ориентированное программирование будет занимать такое же место, какое занимало структурное программирование в 1970-х. но всем будет нравиться. Каждая фирма будет рекламировать свой продукт как зданный по этой технологии. Все программисты будут писать в этом стиле, причем все по-разному. Все менеджеры будут рассуждать о нем. И никто не будет знать, что же это такое" [Wegner, P. [J 1981]] [1]. Данные предсказания продолжают сбываться и в 1990-х годах.
В этой главе мы выясним, чем является и чем не является объектно-ориентированная разработка программ, и в чем отличия этого подхода к проектированию от других с учетом семи перечисленных выше элементов объектной модели.
2.1. Эволюция объектной модели
Тенденции в проектировании
Поколения языков программирования. Оглядываясь на короткую, но колоритную историю развития программирования, нельзя не заметить две сменяющих друг друга тенденции:
-
смещение акцентов от программирования отдельных деталей к программированию более крупных компонент;
-
развитие и совершенствование языков программирования высокого уровня.
Большинство современных коммерческих программных систем больше и существенно сложнее, чем были их предшественники даже несколько лет тому назад. Этот рост сложности вызвал большое число прикладных исследований по методологии проектирования, особенно, по декомпозиции, абстрагированию и иерархиям. Создание более выразительных языков программирования пополнило достижения в этой области. Возникла тенденция перехода от языков, указывающих компьютеру, что делать (императивные языки), к языкам, описывающим ключевые абстракции проблемной области (декларативные языки).
Вегнер сгруппировал некоторые из наиболее известных языков высокого уровня в четыре поколения в зависимости от того, какие языковые конструкции впервые в них появились:
-
Первое поколение (1954-1958)
| FORTRAN I |
Математические формулы |
| ALGOL-58 |
Математические формулы |
| Flowmatic |
Математические формулы |
| IPL V |
Математические формулы |
-
Второе поколение (1959-1961)
| FORTRAN II |
Подпрограммы, раздельная компиляция |
| ALGOL-60 |
Блочная структура, типы данных |
| COBOL |
Описание данных, работа с файлами |
| Lisp |
Обработка списков, указатели, сборка мусора |
-
Третье поколение(1962-1970)
| PL/I |
FORTRAN+ALGOL+COBOL |
| ALGOL-68 |
Более строгий приемник ALGOL-60 |
| Pascal |
Более простой приемник ALGOL-60 |
| Simula |
Классы, абстрактные данные |
-
Потерянное поколение (1970-1980)
Много языков созданных, но мало выживших [Последняя фраза, очевидно, следует евангельскому "...много званных, но мало избранных" (Матф. 22:14). - Примеч. ред.] [2].
В каждом следующем поколении менялись поддерживаемые языками механизмы абстракции. Языки первого поколения ориентировались на научно-инженерные применения, и словарь этой предметной области был почти исключительно математическим. Такие языки, как FORTRAN I, были созданы для упрощения программирования математических формул, чтобы освободить программиста от трудностей ассемблера и машинного кода. Первое поколение языков высокого уровня было шагом, приближающим программирование к предметной области и удаляющим от конкретной машины. Во втором поколении языков основной тенденцией стало развитие алгоритмических абстракций. В это время мощность компьютеров быстро росла, а компьютерная индустрия позволила расширить области их применения, особенно в бизнесе. Главной задачей стало инструктировать машину, что делать: сначала прочти эти анкеты сотрудников, затем отсортируй их и выведи результаты на печать. Это было еще одним шагом к предметной области и от конкретной машины. В конце 60-х годов с появлением транзисторов, а затем интегральных схем, стоимость компьютеров резко снизилась, а их производительность росла почти экспоненциально. Появилась возможность решать все более сложные задачи, но это требовало умения обрабатывать самые разнообразные типы данных. Такие языки как ALGOL-68 и затем Pascal стали поддерживать абстракцию данных. Программисты смогли описывать свои собственные типы данных. Это стало еще одним шагом к предметной области и от привязки к конкретной машине.
70-е годы знаменовались безумным всплеском активности: было создано около двух тысяч различных языков и их диалектов. Неадекватность более ранних языков написанию крупных программных систем стала очевидной, поэтому новые языки имели механизмы, устраняющие это ограничение. Лишь немногие из этих языков смогли выжить (попробуйте найти свежий учебник по языкам Fred, Chaos, Tranquil), однако многие их принципы нашли отражение в новых версиях более ранних языков. Таким образом, мы получили языки Smalltalk (новаторски переработанное наследие Simula), Ada (наследник ALGOL-68 и Pascal с элементами Simula, Alphard и CLU), CLOS (объединивший Lisp, LOOPS и Flavors), C++ (возникший от брака С и Simula) и Eiffel (произошел от Simula и Ada). Наибольший интерес для дальнейшего изложения представляет класс языков, называемых объектными и объектно-ориентированными, которые в наибольшей степени отвечают задаче объектно-ориентированной декомпозиции программного обеспечения.
Топология языков первого и начала второго поколения. Для пояснения сказанного рассмотрим структуры, характерные для каждого поколения. На рис. 2-1 показана топология, типичная для большинства языков первого поколения и первой стадии второго поколения. Говоря "топология", мы имеем в виду основные элементы языка программирования и их взаимодействие. Можно отметить, что для таких языков, как FORTRAN и COBOL, основным строительным блоком является подпрограмма (параграф в терминах COBOL). Программы, реализованные на таких языках, имеют относительно простую структуру, состоящую только из глобальных данных и подпрограмм. Стрелками на рисунке обозначено влияние подпрограмм на данные. В процессе разработки можно логически разделить разнотипные Данные, но механизмы языков практически не поддерживают такого разделения. Ошибка в какой-либо части программы может иметь далеко идущие последствия, так как область данных открыта всем подпрограммам. В больших системах трудно гарантировать целостность данных при внесении изменений в какую-либо часть системы. В процессе эксплуатации уже через короткое время возникает путаница из-за большого количества перекрестных связей между подпрограммами, запутанных схем управления, неясного смысла данных, что угрожает надежности системы и определенно снижает ясность программы.
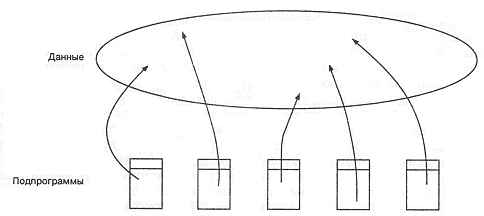 Рис. 2-1. Топология языков первого и начала второго поколения.
Рис. 2-1. Топология языков первого и начала второго поколения.
Топология языков позднего второго и раннего третьего поколения. Начиная с середины 60-х годов стали осознавать роль подпрограмм как важного промежуточного звена между решаемой задачей и компьютером [3]. Шоу отмечает: "Первая программная абстракция, названная процедурной абстракцией, прямо вытекает из этого прагматического взгляда на программные средства... Подпрограммы возникли до 1950 года, но тогда они не были оценены в качестве абстракции... Их рассматривали как средства, упрощающие работу... Но очень скоро стало ясно, что подпрограммы это абстрактные программные функции" [4].
Использование подпрограмм как механизма абстрагирования имело три существенных последствия. Во-первых, были разработаны языки, поддерживавшие разнообразные механизмы передачи параметров. Во-вторых, были заложены основания структурного программирования, что выразилось в языковой поддержке механизмов вложенности подпрограмм и в научном исследовании структур управления и областей видимости. В-третьих, возникли методы структурного проектирования, стимулирующие разработчиков создавать большие системы, используя подпрограммы как готовые строительные блоки. Архитектура языков программирования этого периода (рис. 2-2), как и следовало ожидать, представляет собой вариации на темы предыдущего поколения. В нее внесены кое-какие усовершенствования, в частности, усилено управление алгоритмическими абстракциями, но остается нерешенной проблема программирования "в большом" и проектирования данных.
Топология языков конца третьего поколения. Начиная с FORTRAN II и далее, для решения задач программирования "в большом" начал развиваться новый важный механизм структурирования. Разрастание программных проектов означало увеличение размеров и коллективов программистов, а, следовательно, необходимость независимой разработки отдельных частей проекта. Ответом на эту потребность стал отдельно компилируемый модуль, который сначала был просто более или менее случайным набором данных и подпрограмм (рис. 2-3). В такие модули собирали подпрограммы, которые, как казалось, скорее всего будут изменяться совместно, и мало кто рассматривал их как новую технику абстракции. В большинстве языков этого поколения, хотя и поддерживалось модульное программирование, но не вводилось никаких правил, обеспечивающих согласование интерфейсов модулей. Программист, сочиняющий подпрограмму в одном из модулей, мог, например, ожидать, что ее будут вызывать с тремя параметрами: действительным числом, массивом из десяти элементов и целым числом, обозначающим логическое значение. Но в каком-то другом модуле, вопреки предположениям автора, эта подпрограмма могла по ошибке вызываться с фактическими параметрами в виде: целого числа, массива из пяти элементов и отрицательного числа. Аналогично, один из модулей мог завести общую область данных и считать, что это его собственная область, а другой модуль мог нарушить это предположение, свободно манипулируя с этими данными. К сожалению, поскольку большинство языков предоставляло в лучшем случае рудиментарную поддержку абстрактных данных и типов, такие ошибки выявлялись только при выполнении программы.
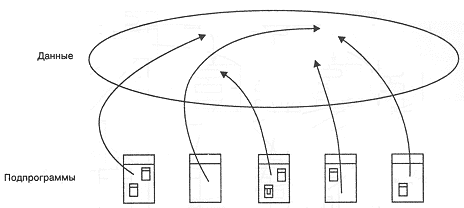 Рис. 2-2. Топология языков позднего второго и раннего третьего поколения.
Рис. 2-2. Топология языков позднего второго и раннего третьего поколения.
Топология объектных и объектно-ориентированных языков. Значение абстрактных типов данных в разрешении проблемы сложности систем хорошо выразил Шанкар: "Абстрагирование, достигаемое посредством использования процедур, хорошо подходит для описания абстрактных действий, но не годится для описания абстрактных объектов. Это серьезный недостаток, так как во многих практических ситуациях сложность объектов, с которыми нужно работать, составляет основную часть сложности всей задачи" [5]. Осознание этого влечет два важных вывода. Во-первых, возникают методы проектирования на основе потоков данных, которые вносят упорядоченность в абстракцию данных в языках, ориентированных на алгоритмы. Во-вторых, появляется теория типов, которая воплощается в таких языках, как Pascal.
Естественным завершением реализации этих идей, начавшейся с языка Simula и развитой в последующих языках в 1970-1980-е годы, стало сравнительно недавнее появление таких языков, как Smalltalk, Object Pascal, C++, CLOS, Ada и Eiffel. По причинам, которые мы вскоре объясним, эти языки получили название объектных или объектно-ориентированных. На рис. 2-4 приведена топология таких языков применительно к задачам малой и средней степени сложности. Основным элементом конструкции в указанных языках служит модуль, составленный из логически связанных классов и объектов, а не подпрограмма, как в языках первого поколения.
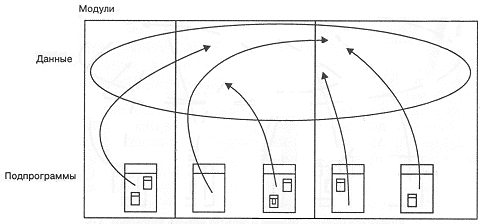 Рис. 2-3. Топология языков конца третьего поколения.
Рис. 2-3. Топология языков конца третьего поколения.
Другими словами: "Если процедуры и функции - глаголы, а данные - существительные, то процедурные программы строятся из глаголов, а объектно-ориентированные - из существительных" [6]. По этой же причине структура программ малой и средней сложности при объектно-ориентированном подходе представляется графом, а не деревом, как в случае алгоритмических языков. Кроме того, уменьшена или отсутствует область глобальных данных. Данные и действия организуются теперь таким образом, что основными логическими строительными блоками наших систем становятся классы и объекты, а не алгоритмы.
В настоящее время мы продвинулись много дальше программирования "в большом" и предстали перед программированием "в огромном". Для очень сложных систем классы, объекты и модули являются необходимыми, но не достаточными средствами абстракции. К счастью, объектный подход масштабируется и может быть применен на все более высоких уровнях. Кластеры абстракций в больших системах могут представляться в виде многослойной структуры. На каждом уровне можно выделить группы объектов, тесно взаимодействующих для решения задачи более высокого уровня абстракции. Внутри каждого кластера мы неизбежно найдем такое же множество взаимодействующих абстракций (рис. 2-5). Это соответствует подходу к сложным системам, изложенному в главе 1.
Основные положения объектной модели
Методы структурного проектирования помогают упростить процесс разработки сложных систем за счет использования алгоритмов как готовых строительных блоков. Аналогично, методы объектно-ориентированного проектирования созданы, чтобы помочь разработчикам применять мощные выразительные средства объектного и объектно-ориентированного программирования, использующего в качестве блоков классы и объекты.
Но в объектной модели отражается и множество других факторов. Как показано во врезке ниже, объектный подход зарекомендовал себя как унифицирующая идея всей компьютерной науки, применимая не только в программировании, но также в проектировании интерфейса пользователя, баз данных и даже архитектуры компьютеров. Причина такой широты в том, что ориентация на объекты позволяет нам справляться со сложностью систем самой разной природы.
 Рис. 2-4. Топология малых и средних приложений в объектных и объектно-ориентированных языках.
Рис. 2-4. Топология малых и средних приложений в объектных и объектно-ориентированных языках.
Объектно-ориентированный анализ и проектирование отражают эволюционное, а не революционное развитие проектирования; новая методология не порывает с прежними методами, а строится с учетом предшествующего опыта. К сожалению, большинство программистов в настоящее время формально и неформально натренированы на применение только методов структурного проектирования. Разумеется, многие хорошие проектировщики создали и продолжают совершенствовать большое количество программных систем на основе этой методологии. Однако алгоритмическая декомпозиция помогает только до определенного предела, и обращение к объектно-ориентированной декомпозиции необходимо. Более того, при попытках использовать такие языки, как C++ или Ada, в качестве традиционных, алгоритмически ориентированных, мы не только теряем их внутренний потенциал - скорее всего результат будет даже хуже, чем при использовании обычных языков С и Pascal. Дать электродрель плотнику, который не слышал об электричестве, значит использовать ее в качестве молотка. Он согнет несколько гвоздей и разобьет себе пальцы, потому что электродрель мало пригодна для замены молотка.
OOP, OOD и ООА
Унаследовав от многих предшественников, объектный подход, к сожалению, перенял и запутанную терминологию. Программист в Smalltalk пользуется термином метод, в C++ - термином виртуальная функция, в CLOS - обобщенная функция.
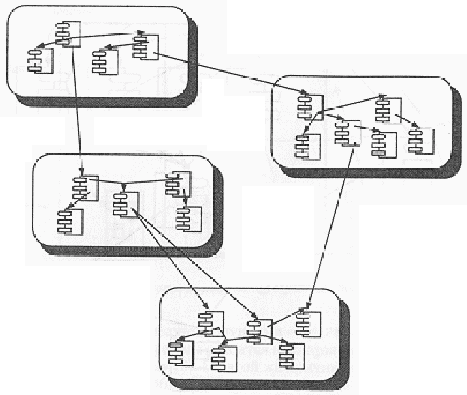 Рис. 2-5. Топология больших приложений в объектных и объектно-ориентированных языках.
Рис. 2-5. Топология больших приложений в объектных и объектно-ориентированных языках.
В Object Pascal используется термин приведение типов, а в языке Ada то же самое называется преобразование типов. Чтобы уменьшить путаницу, следует определить, что является объектно-ориентированным, а что - нет. Определение наиболее употребительных терминов и понятий вы найдете в глоссарии в конце книги.
Термин объектно-ориентированный, по мнению Бхаскара, "затаскан до потери смысла, как "материнство", "яблочный пирог" и "структурное программирование"" [7]. Можно согласиться, что понятие объекта является центральным во всем, что относится к объектно-ориентированной методологии. В главе 1 мы определили объект как осязаемую сущность, которая четко проявляет свое поведение. Стефик и Бобров определяют объекты как "сущности, объединяющие процедуры и данные, так как они производят вычисления и сохраняют свое локальное состояние" [8]. Определение объекта как сущности в какой-то мере отвечает на вопрос, но все же главным в понятии объекта является объединение идей абстракции данных и алгоритмов. Джонс уточняет это понятие следующим образом: "В объектном подходе акцент переносится на конкретные характеристики физической или абстрактной системы, являющейся предметом программного моделирования... Объекты обладают целостностью, которая не должна - а, в действительности, не может - быть нарушена. Объект может только менять состояние, вести себя, управляться или становиться в определенное отношение к другим объектам. Иначе говоря, свойства, которые характеризуют объект и его поведение, остаются неизменными. Например, лифт характеризуется теми неизменными свойствами, что он может двигаться вверх и вниз, оставаясь в пределах шахты... Любая модель должна учитывать эти свойства лифта, так как они входят в его определение" [32].
| Основные положения объектной модели
Йонесава и Токоро свидетельствуют: "термин "объект" появился практически независимо в различных областях, связанных с компьютерами, и почти одновременно в начале 70-х годов для обозначения того, что может иметь различные проявления, оставаясь целостным. Для того, чтобы уменьшить сложность программных систем, объектами назывались компоненты системы или фрагменты представляемых знании" [9]. По мнению Леви, объектно-ориентированный подход был связан со следующими событиями:
-
"прогресс в области архитектуры ЭВМ;
-
развитие языков программирования, таких как Simula, Smalltalk, CLU, Ada;
-
развитие методологии программирования, включая принципы модульности и скрытия
данных" [10].
К этому еще следует добавить три момента, оказавшие влияние на становление
объектного подхода:
-
развитие теории баз данных;
-
исследования в области искусственного интеллекта;
-
достижения философии и теории познания.
Понятие "объект" впервые было использовано более 20 лет назад при конструировании компьютеров с descriptor-based и capability-based архитектурами [11]. В этих работах делались попытки отойти от традиционной архитектуры фон Неймана и преодолеть барьер между высоким уровнем программной абстракции и низким уровнем ЭВМ [12]. По мнению сторонников этих подходов, тогда были созданы более качественные средства, обеспечивающие: лучшее выявление ошибок, большую эффективность реализации программ, сокращение набора инструкций, упрощение компиляции, снижение объема требуемой памяти. Ряд компьютеров имеет объектно-ориентированную архитектуру: Burroughs 5000, Plessey 250, Cambridge CAP [13], SWARD [14], Intel 432 [15], Caltech's СОМ [16], IBM System/38 [17], Rational R1000, BiiN 40 и 60.
С объектно-ориентированной архитектурой тесно связаны объектно-ориентированные операционные системы (ОС). Дейкстра, работая над мультипрограммной системой THE, впервые ввел понятие машины с уровнями состояния в качестве средства построения системы [18]. Среди первых объектно-ориентированных ОС следует отметить: Plessey/System 250 (для мультипроцессора Plessey 250), Hydra (для CMU C.mmp), CALTSS (для CDC 6400), CAP (для компьютера Cambridge CAP), UCLA Secure UNIX (для PDP 11/45 и 11/70), StarOS (для CMU Cm*), Medusa (также для CMU Cm*) и iMAX (для Intel 432) [19]. Следующее поколение операционных систем, таких, как Microsoft Cairo и Taligent Pink, будет, по всей видимости, объектно-ориентированным.
Наиболее значительный вклад в объектный подход внесен объектными и объектно-ориентированными языками программирования. Впервые понятия классов и объектов введены в языке Simula 67. Система Flex и последовавшие за ней диалекты Smalltalk-72, -74, -76 и, наконец, -80, взяв за основу методы Simula, довели их до логического завершения, выполняя все действия на основе классов. В 1970-х годах создан ряд языков, реализующих идею абстракции данных: Alphard, CLU, Euclid, Gypsy, Mesa и Modula. Затем методы, используемые в языках Simula и Smalltalk, были использованы в традиционных языках высокого уровня. Внесение объектно-ориентированного подхода в С привело к возникновению языков C++ и Objective С. На основе языка Pascal возникли Object Pascal, Eiffel и Ada. Появились диалекты LISP, такие, как Flavors, LOOPS и CLOS (Common LISP Object System), с возможностями языков Simula и Smalltalk. Более подробно особенности этих языков изложены в приложении.
Первым, кто указал на необходимость построения систем в виде структурированных абстракций, был Дейкстра. Позднее Парнас ввел идею скрытия информации [20], а в 70-х годах ряд исследователей, главным образом Лисков и Жиль [21], Гуттаг [22], и Шоу [23], разработал механизмы абстрактных типов данных. Хоар дополнил эти подходы теорией типов и подклассов [24].
Развивавшиеся достаточно независимо технологии построения баз данных также оказали влияние на объектный подход [25], в первую очередь благодаря так называемой модели "сущность-отношение" (ER, entity-relationship) [26]. В моделях ER, впервые предложенных Ченом [27], моделирование происходит в терминах сущностей, их атрибутов и взаимоотношений.
Разработчики способов представления данных в области искусственного интеллекта также внесли свой вклад в понимание объектно-ориентированных абстракций. В 1975 г. Мински выдвинул теорию фреймов для представления реальных объектов в системах распознавания образов и естественных языков [28]. Фреймы стали использоваться в качестве архитектурной основы в различных интеллектуальных системах.
Объектный подход известен еще издавна. Грекам принадлежит идея о том, что мир можно рассматривать в терминах как объектов, так и событий. А в XVII веке Декарт отмечал, что люди обычно имеют объектно-ориентированный взгляд на мир [29]. В XX веке эту тему развивала Рэнд в своей философии объективистской эпистемологии [30]. Позднее Мински предложил модель человеческого мышления, в которой разум человека рассматривается как общность различно мыслящих агентов [31]. Он доказывает, что только совместное действие таких агентов приводит к осмысленному поведению человека. |
Объектно-ориентированное программирование. Что же такое объектно-ориентированное программирование (object-oriented programming, OOP)? Мы определяем его следующим образом:
Объектно-ориентированное программирование - это методология программирования, основанная на представлении программы в виде совокупности объектов, каждый из которых является экземпляром определенного класса, а классы образуют иерархию наследования.
В данном определении можно выделить три части: 1) OOP использует в качестве базовых элементов объекты, а не алгоритмы (иерархия "быть частью", которая была определена в главе 1); 2) каждый объект является экземпляром какого-либо определенного класса; 3) классы организованы иерархически (см. понятие об иерархии "is а" там же). Программа будет объектно-ориентированной только при соблюдении всех трех указанных требований. В частности, программирование, не основанное на иерархических отношениях, не относится к OOP, а называется программированием на основе абстрактных типов данных.
В соответствии с этим определением не все языки программирования являются объектно-ориентированными. Страуструп определил так: "если термин объектно-ориентированный язык вообще что-либо означает, то он должен означать язык, имеющий средства хорошей поддержки объектно-ориентированного стиля программирования... Обеспечение такого стиля в свою очередь означает, что в языке удобно пользоваться этим стилем. Если написание программ в стиле OOP требует специальных усилий или оно невозможно совсем, то этот язык не отвечает требованиям OOP" [33]. Теоретически возможна имитация объектно-ориентированного программирования на обычных языках, таких, как Pascal и даже COBOL или ассемблер, но это крайне затруднительно. Карделли и Вегнер говорят, что: "язык программирования является объектно-ориентированным тогда и только тогда, когда выполняются следующие условия:
-
Поддерживаются объекты, то есть абстракции данных, имеющие интерфейс в виде именованных операций и собственные данные, с ограничением доступа к ним.
-
Объекты относятся к соответствующим типам (классам).
-
Типы (классы) могут наследовать атрибуты супертипов (суперклассов)" [34].
Поддержка наследования в таких языках означает возможность установления отношения "is-a" ("есть", "это есть", " - это"), например, красная роза - это цветок, а цветок - это растение. Языки, не имеющие таких механизмов, нельзя отнести к объектно-ориентированным. Карделли и Вегнер назвали такие языки объектными, но не объектно-ориентированными. Согласно этому определению объектно-ориентированными языками являются Smalltalk, Object Pascal, C++ и CLOS, a Ada - объектный язык. Но, поскольку объекты и классы являются элементами обеих групп языков, желательно использовать и в тех, и в других методы объектно-ориентированного проектирования.
Объектно-ориентированное проектирование. Программирование прежде всего подразумевает правильное и эффективное использование механизмов конкретных языков программирования. Проектирование, напротив, основное внимание уделяет правильному и эффективному структурированию сложных систем. Мы определяем объектно-ориентированное проектирование следующим образом:
Объектно-ориентированное проектирование - это методология проектирования, соединяющая в себе процесс объектной декомпозиции и приемы представления логической и физической, а также статической и динамической моделей проектируемой системы.
В данном определении содержатся две важные части: объектно-ориентированное проектирование 1) основывается на объектно-ориентированной декомпозиции; 2) использует многообразие приемов представления моделей, отражающих логическую (классы и объекты) и физическую (модули и процессы) структуру системы, а также ее статические и динамические аспекты.
Именно объектно-ориентированная декомпозиция отличает объектно-ориентированное проектирование от структурного; в первом случае логическая структура системы отражается абстракциями в виде классов и объектов, во втором - алгоритмами. Иногда мы будем использовать аббревиатуру OOD, object-oriented design, для обозначения метода объектно-ориентированного проектирования, изложенного в этой книге.
Объектно-ориентированный анализ. На объектную модель повлияла более ранняя модель жизненного цикла программного обеспечения. Традиционная техника структурного анализа, описанная в работах Де Марко [35], Иордана [36], Гейна и Сарсона [37], а с уточнениями для режимов реального времени у Варда и Меллора [38] и Хотли и Пирбхая [39], основана на потоках данных в системе. Объектно-ориентированный анализ (или OOA, object-oriented analysis) направлен на создание моделей реальной действительности на основе объектно-ориентированного мировоззрения.
Объектно-ориентированный анализ - это методология, при которой требования к системе воспринимаются с точки зрения классов и объектов, выявленных в предметной области.
Как соотносятся ООА, OOD и OOP? На результатах ООА формируются модели, на которых основывается OOD; OOD в свою очередь создает фундамент для окончательной реализации системы с использованием методологии OOP.
2.2. Составные части объектного подхода
Парадигмы программирования
Дженкинс и Глазго считают, что "в большинстве своем программисты используют в работе один язык программирования и следуют одному стилю. Они программируют в парадигме, навязанной используемым ими языком. Часто они оставляют в стороне альтернативные подходы к цели, а следовательно, им трудно увидеть преимущества стиля, более соответствующего решаемой задаче" [40]. Бобров и Стефик так определили понятие стиля программирования: "Это способ построения программ, основанный на определенных принципах программирования, и выбор подходящего языка, который делает понятными программы, написанные в этом стиле" [41]. Эти же авторы выявили пять основных разновидностей стилей программирования, которые перечислены ниже вместе с присущими им видами абстракций:
| ® процедурно-ориентированный |
алгоритмы |
| ® объектно-ориентированный |
классы и объекты |
| ® логико-ориентированный |
цели, часто выраженные в терминах исчисления предикатов |
| ® ориентированный на правила |
правила "если-то" |
| ® ориентированный на ограничения |
инвариантные соотношения |
Невозможно признать какой-либо стиль программирования наилучшим во всех областях практического применения. Например, для проектирования баз знаний более пригоден стиль, ориентированный на правила, а для вычислительных задач - процедурно-ориентированный. По нашему опыту объектно-ориентированный стиль является наиболее приемлемым для широчайшего круга приложений; действительно, эта парадигма часто служит архитектурным фундаментом, на котором мы основываем другие парадигмы.
Каждый стиль программирования имеет свою концептуальную базу. Каждый стиль требует своего умонастроения и способа восприятия решаемой задачи. Для объектно-ориентированного стиля концептуальная база - это объектная модель. Она имеет четыре главных элемента:
-
абстрагирование;
-
инкапсуляция;
-
модульность;
-
иерархия.
Эти элементы являются главными в том смысле, что без любого из них модель не будет объектно-ориентированной. Кроме главных, имеются еще три дополнительных элемента:
-
типизация;
-
параллелизм;
-
сохраняемость.
Называя их дополнительными, мы имеем в виду, что они полезны в объектной модели, но не обязательны.
Без такой концептуальной основы вы можете программировать на языке типа Smalltalk, Object Pascal, C++, CLOS, Eiffel или Ada, но из-под внешней красоты будет выглядывать стиль FORTRAN, Pascal или С. Выразительная способность объектно-ориентированного языка будет либо потеряна, либо искажена. Но еще более существенно, что при этом будет мало шансов справиться со сложностью решаемых задач.
Абстрагирование
Смысл абстрагирования. Абстрагирование является одним из основных методов, используемых для решения сложных задач. Хоар считает, что "абстрагирование проявляется в нахождении сходств между определенными объектами, ситуациями или процессами реального мира, и в принятии решений на основе этих сходств, отвлекаясь на время от имеющихся различий" [42]. Шоу определила это понятие так: "Упрощенное описание или изложение системы, при котором одни свойства и детали выделяются, а другие опускаются. Хорошей является такая абстракция, которая подчеркивает детали, существенные для рассмотрения и использования, и опускает те, которые на данный момент несущественны" [43]. Берзинс, Грей и Науман рекомендовали, чтобы "идея квалифицировалась как абстракция только, если она может быть изложена, понята и проанализирована независимо от механизма, который будет в дальнейшем принят для ее реализации" [44]. Суммируя эти разные точки зрения, получим следующее определение абстракции:
Абстракция выделяет существенные характеристики некоторого объекта,
отличающие его от всех других видов объектов и, таким образом, четко определяет
его концептуальные границы с точки зрения наблюдателя.
Абстрагирование концентрирует внимание на внешних особенностях объекта и позволяет отделить самые существенные особенности поведения от несущественных. Абельсон и Суссман назвали такое разделение смысла и реализации барьером абстракции [45], который основывается на принципе минимизации связей, когда интерфейс объекта содержит только существенные аспекты поведения и ничего больше [46]. Мы считаем полезным еще один дополнительный принцип, называемый принципом наименьшего удивления, согласно которому абстракция должна охватывать все поведение объекта, но не больше и не меньше, и не привносить сюрпризов или побочных эффектов, лежащих вне ее сферы применимости.
Выбор правильного набора абстракций для заданной предметной области представляет собой главную задачу объектно-ориентированного проектирования. Ввиду важности этой темы ей целиком посвящена глава 4.
По мнению Сейдвица и Старка "существует целый спектр абстракций, начиная с объектов, которые почти точно соответствуют реалиям предметной области, и кончая объектами, не имеющими право на существование" [47]. Вот эти абстракции, начиная от наиболее полезных к наименее полезным:
| ® Абстракция сущности |
Объект представляет собой полезную модель некой сущности в предметной области |
| ® Абстракция поведения |
Объект состоит из обобщенного множества операций |
| ® Абстракция виртуальной машины |
Объект группирует операции, которые либо вместе используются более высоким уровнем управления, либо сами используют некоторый набор операций более низкого уровня |
| ® Произвольная абстракция |
Объект включает в себя набор операций, не имеющих друг с другом ничего общего |
Мы стараемся строить абстракции сущности, так как они прямо соответствуют сущностям предметной области.
Клиентом называется любой объект, использующий ресурсы другого объекта (называемого сервером). Мы будем характеризовать поведение объекта услугами, которые он оказывает другим объектам, и операциями, которые он выполняет над другими объектами. Такой подход концентрирует внимание на внешних проявлениях объекта и приводит к идее, которую Мейер назвал контрактной моделью программирования [48]: внешнее проявление объекта рассматривается с точки зрения его контракта с другими объектами, в соответствии с этим должно быть выполнено и его внутреннее устройство (часто во взаимодействии с другими объектами). Контракт фиксирует все обязательства, которые объект-сервер имеет перед объектом-клиентом. Другими словами, этот контракт определяет ответственность объекта - то поведение, за которое он отвечает [49].
Каждая операция, предусмотренная этим контрактом, однозначно определяется ее формальными параметрами и типом возвращаемого значения. Полный набор операций, которые клиент может осуществлять над другим объектом, вместе с правильным порядком, в котором эти операции вызываются, называется протоколом. Протокол отражает все возможные способы, которыми объект может действовать или подвергаться воздействию, полностью определяя тем самым внешнее поведение абстракции со статической и динамической точек зрения.
 Абстракция фокусируется на существенных с точки зрения наблюдателя характеристиках объекта.
Абстракция фокусируется на существенных с точки зрения наблюдателя характеристиках объекта.
Центральной идеей абстракции является понятие инварианта. Инвариант - это некоторое логическое условие, значение которого (истина или ложь) должно сохраняться. Для каждой операции объекта можно задать предусловия (инварианты предполагаемые операцией) и постусловия (инварианты, которым удовлетворяет операция). Изменение инварианта нарушает контракт, связанный с абстракцией. В частности, если нарушено предусловие, то клиент не соблюдает свои обязательства и сервер не может выполнить свою задачу правильно. Если же нарушено постусловие, то свои обязательства нарушил сервер, и клиент не может более ему доверять. В случае нарушения какого-либо условия возбуждается исключительная ситуация. Как мы увидим далее, некоторые языки имеют средства для работы с исключительными ситуациями: объекты могут возбуждать исключения, чтобы запретить дальнейшую обработку и предупредить о проблеме другие объекты, которые в свою очередь могут принять на себя перехват исключения и справиться с проблемой.
Заметим, что понятия операция, метод и функция-член происходят от различных традиций программирования (Ada, Smalltalk и C++ соответственно). Фактически они обозначают одно и то же и в дальнейшем будут взаимозаменяемы.
Все абстракции обладают как статическими, так и динамическими свойствами. Например, файл как объект требует определенного объема памяти на конкретном устройстве, имеет имя и содержание. Эти атрибуты являются статическими свойствами. Конкретные же значения каждого из перечисленных свойств динамичны и изменяются в процессе использования объекта: файл можно увеличить или уменьшить, изменить его имя и содержимое. В процедурном стиле программирования действия, изменяющие динамические характеристики объектов, составляют суть программы. Любые события связаны с вызовом подпрограмм и с выполнением операторов. Стиль программирования, ориентированный на правила, характеризуется тем, что под влиянием определенных условий активизируются определенные правила, которые в свою очередь вызывают другие правила, и т.д. Объектно-ориентированный стиль программирования связан с воздействием на объекты (в терминах Smalltalk с передачей объектам сообщений). Так, операция над объектом порождает некоторую реакцию этого объекта. Операции, которые можно выполнить по отношению к данному объекту, и реакция объекта на внешние воздействия определяют поведение этого объекта.
Примеры абстракций. Для иллюстрации сказанного выше приведем несколько примеров. В данном случае мы сконцентрируем внимание не столько на выделении абстракций для конкретной задачи (это подробно рассмотрено в главе 4), сколько на способе выражения абстракций.
В тепличном хозяйстве, использующем гидропонику, растения выращиваются на питательном растворе без песка, гравия или другой почвы. Управление режимом работы парниковой установки - очень ответственное дело, зависящее как от вида выращиваемых культур, так и от стадии выращивания. Нужно контролировать целый ряд факторов: температуру, влажность, освещение, кислотность (показатель рН) и концентрацию питательных веществ. В больших хозяйствах для решения этой задачи часто используют автоматические системы, которые контролируют и регулируют указанные факторы. Попросту говоря, цель автоматизации состоит здесь в том, чтобы при минимальном вмешательстве человека добиться соблюдения режима выращивания.
Одна из ключевых абстракций в такой задаче - датчик. Известно несколько разновидностей датчиков. Все, что влияет на урожай, должно быть измерено, так что мы должны иметь датчики температуры воды и воздуха, влажности, рН, освещения и концентрации питательных веществ. С внешней точки зрения датчик температуры - это объект, который способен измерять температуру там, где он расположен. Что такое температура? Это числовой параметр, имеющий ограниченный диапазон значений и определенную точность, означающий число градусов по Фаренгейту, Цельсию или Кельвину. Что такое местоположение датчика? Это некоторое идентифицируемое место в теплице, температуру в котором нам необходимо знать; таких мест, вероятно, немного. Для датчика температуры существенно не столько само местоположение, сколько тот факт, что данный датчик расположен именно в данном месте и это отличает его от других датчиков. Теперь можно задать вопрос о том, каковы обязанности датчика температуры? Мы решаем, что датчик должен знать температуру в своем местонахождении и сообщать ее по запросу. Какие же действия может выполнять по отношению к датчику клиент? Мы принимаем решение о том, что клиент может калибровать датчик и получать от него значение текущей температуры.
Для демонстрации проектных решений будет использован язык C++. Читатели, недостаточно знакомые с этим языком, а также желающие уточнить свои знания по другим объектным и объектно-ориентированным языкам, упоминаемым в этой книге, могут найти их краткие описания с примерами в приложении. Итак, вот описания, задающие абстрактный датчик температуры на C++.
// Температура по Фаренгейту
typedef float Temperature;
// Число, однозначно определяющее положение датчика
typedef unsigned int Location;
class TemperatureSensor {
public:
TemperatureSensor (Location);
~TemperatureSensor();
void calibrate(Temperature actualTemperature);
Temperature currentTemperature() const;
private:
...
};
Здесь два оператора определения типов Temperature и Location вводят удобные псевдонимы для простейших типов, и это позволяет нам выражать свои абстракции на языке предметной области [К сожалению, конструкция typedef не определяет нового типа данных и не обеспечивает его защиты. Например, следующее описание в C++: "typedef int Count;" просто вводит синоним для примитивного типа int. Как мы увидим в следующем разделе, другие языки, такие как Ada и Eiffel, имеют более изощренную семантику в отношении строгой типизации базовых типов]. Temperature - это числовой тип данных в формате с плавающей точкой для записи температур в шкале Фаренгейта. Значения типа Location обозначают места фермы, где могут располагаться температурные датчики.
Класс TemperatureSensor - это только спецификация датчика; настоящая его начинка скрыта в его закрытой (private) части. Класс TemperatureSensor это еще не объект. Собственно датчики - это его экземпляры, и их нужно создать, прежде чем с ними можно будет оперировать. Например, можно написать так:
Temperature temperature;
TemperatureSensor greenhouse1Sensor(1);
TemperatureSensor greenhouse2Sensor(2);
temperature = greenhouse1Sensor.currentTemperature();
Рассмотрим инварианты, связанные с операцией currentTemperature. Предусловие включает предположение, что датчик установлен в правильным месте в теплице, а постусловие - что датчик возвращает значение температуры в градусах Фаренгейта.
До сих пор мы считали датчик пассивным: кто-то должен запросить у него температуру, и тогда он ответит. Однако есть и другой, столь же правомочный подход. Датчик мог бы активно следить за температурой и извещать другие объекты, когда ее отклонение от заданного значения превышает заданный уровень. Абстракция от этого меняется мало: всего лишь несколько иначе формулируется ответственность объекта. Какие новые операции нужны ему в связи с этим? Обычной идиомой для таких случаев является обратный вызов. Клиент предоставляет серверу функцию (функцию обратного вызова), а сервер вызывает ее, когда считает нужным. Здесь нужно написать что-нибудь вроде:
class ActiveTemperatureSensor {
public:
ActiveTemperatureSensor (Location,
void (*f)(Location, Temperature));
~ActiveTemperatureSensor();
void calibrate(Temperature actualTemperature);
void establishSetpoint(Temperature setpoint,
Temperature delta);
Temperature currentTemperature() const;
private:
...
};
Новый класс ActiveTemperatureSensor стал лишь чуть сложнее, но вполне адекватно выражает новую абстракцию. Создавая экземпляр датчика, мы передаем ему при инициализации не только место, но и указатель на функцию обратного вызова, параметры которой определяют место установки и температуру. Новая функция установки establishSetpoint позволяет клиенту изменять порог срабатывания датчика температуры, а ответственность датчика состоит в том, чтобы вызывать функцию обратного вызова каждый раз, когда текущая температура actualTemperature отклоняется от setpoint больше чем на delta. При этом клиенту становится известно место срабатывания и температура в нем, а дальше уже он сам должен знать, что с этим делать.
Заметьте, что клиент по-прежнему может запрашивать температуру по собственной инициативе. Но что если клиент не произведет инициализацию, например, не задаст допустимую температуру? При проектировании мы обязательно должны решить этот вопрос, приняв какое-нибудь разумное допущение: пусть считается, что интервал допустимых изменений температуры бесконечно широк.
Как именно класс ActiveTemperatureSensor выполняет свои обязательства, зависит от его внутреннего представления и не должно интересовать внешних клиентов. Это определяется реализацией его закрытой части и функций-членов.
Рассмотрим теперь другой пример абстракции. Для каждой выращиваемой культуры должен быть задан план выращивания, описывающий изменение во времени температуры, освещения, подкормки и ряда других факторов, обеспечивающих высокий урожай. Поскольку такой план является частью предметной области, вполне оправдана его реализация в виде абстракции.
Для каждой выращиваемой культуры существует свой отдельный план, но общая форма планов у всех культур одинакова. Основу плана выращивания составляет таблица, сопоставляющая моментам времени перечень необходимых действий. Например, для некоторой культуры на 15-е сутки роста план предусматривает поддержание в течении 16 часов температуры 78ЂF, из них 14 часов с освещением, а затем понижение температуры до 65ЂF на остальное время суток. Кроме того, может потребоваться внесение удобрений в середине дня, чтобы поддержать заданное значение кислотности.
Таким образом, план выращивания отвечает за координацию во времени всех действий, необходимых при выращивании культуры. Наше решение заключается в том, чтобы не поручать абстракции плана само выполнение плана, - это будет обязанностью другой абстракции. Так мы ясно разделим понятия между различными частями системы и ограничим концептуальный размер каждой отдельной абстракции.
С точки зрения интерфейса объекта-плана, клиент должен иметь возможность устанавливать детали плана, изменять план и запрашивать его. Например, объект может быть реализован с интерфейсом "человек-компьютер" и ручным изменением плана. Объект, который содержит детали плана выращивания, должен уметь изменять сам себя. Кроме того, должен существовать объект-исполнитель плана, умеющий читать план. Как видно из дальнейшего описания, ни один объект не обособлен, а все они взаимодействуют для обеспечения общей цели. Исходя из такого подхода, определяются границы каждого объекта-абстракции и протоколы их связи.
На C++ план выращивания будет выглядеть следующим образом. Сначала введем новые типы данных, приближая наши абстракции к словарю предметной области (день, час, освещение, кислотность, концентрация):
// Число, обозначающее день года
typedef unsigned int Day;
// Число, обозначающее час дня
typedef unsigned int Hour;
// Булевский тип
enum Lights {OFF, ON};
// Число, обозначающее показатель кислотности в диапазоне от
1 до 14
typedef float pH;
// Число, обозначающее концентрацию в процентах: от 0 до 100
typedef float Concentration;
Далее, в тактических целях, опишем следующую структуру:
// Структура, определяющая условия в теплице
struct Condition {
Temperature temperature;
Lights lighting;
pH acidity;
Concentration concentration;
};
Мы использовали структуру, а не класс, поскольку Condition - это просто механическое объединение параметров, без какого-либо внутреннего поведения, и более богатая семантика класса здесь не нужна.
Наконец, вот и план выращивания:
class GrowingPlan (
public:
GrowingPlan (char *name);
virtual ~GrowingPlan();
void clear();
virtual void establish(Day, Hour, const Condition&);
const char* name() const;
const Condition& desiredConditions(Day, Hour) const;
protected:
...
};
Заметьте, что мы предусмотрели одну новую обязанность: каждый план имеет имя, и его можно устанавливать и запрашивать. Кроме того заметьте, что операция establish описана как virtual для того, чтобы подклассы могли ее переопределять.
В открытую (public) часть описания вынесены конструктор и деструктор
объекта (определяющие процедуры его порождения и уничтожения), две процедуры
модификации (очистка всего плана clear и определение элементов плана establish)
и два селектора-определителя состояния (функции name и desiredCondition).
Мы опустили в описании закрытую часть класса, заменив ее многоточием, поскольку
сейчас нам важны внешние ответственности, а не внутреннее представление
класса.
Инкапсуляция
Что это значит? Хотя мы описывали нашу абстракцию GrowingPlan как сопоставление действий моментам времени, она не обязательно должна быть реализована буквально как таблица данных. Действительно, клиенту нет никакого дела до реализации класса, который его обслуживает, до тех пор, пока тот соблюдает свои обязательства. На самом деле, абстракция объекта всегда предшествует его реализации. А после того, как решение о реализации принято, оно должно трактоваться как секрет абстракции, скрытый от большинства клиентов. Как мудро замечает Ингалс: "Никакая часть сложной системы не должна зависеть от внутреннего устройства какой-либо другой части" [50]. В то время, как абстракция "помогает людям думать о том, что они делают", инкапсуляция "позволяет легко перестраивать программы" [51].
Абстракция и инкапсуляция дополняют друг друга: абстрагирование направлено на наблюдаемое поведение объекта, а инкапсуляция занимается внутренним устройством. Чаще всего инкапсуляция выполняется посредством скрытия информации, то есть маскировкой всех внутренних деталей, не влияющих на внешнее поведение. Обычно скрываются и внутренняя структура объекта и реализация его методов.
Инкапсуляция, таким образом, определяет четкие границы между различными абстракциями. Возьмем для примера структуру растения: чтобы понять на верхнем уровне действие фотосинтеза, вполне допустимо игнорировать такие подробности, как функции корней растения или химию клеточных стенок. Аналогичным образом при проектировании базы данных принято писать программы так, чтобы они не зависели от физического представления данных; вместо этого сосредотачиваются на схеме, отражающей логическое строение данных [52]. В обоих случаях объекты защищены от деталей реализации объектов более низкого уровня.
Дисков прямо утверждает, что "абстракция будет работать только вместе с инкапсуляцией" [53]. Практически это означает наличие двух частей в классе: интерфейса и реализации. Интерфейс отражает внешнее поведение объекта, описывая абстракцию поведения всех объектов данного класса. Внутренняя реализация описывает представление этой абстракции и механизмы достижения желаемого поведения объекта. Принцип разделения интерфейса и реализации соответствует сути вещей: в интерфейсной части собрано все, что касается взаимодействия данного объекта с любыми другими объектами; реализация скрывает от других объектов все детали, не имеющие отношения к процессу взаимодействия объектов. Бритон и Парнас назвали такие детали "тайнами абстракции" [54].
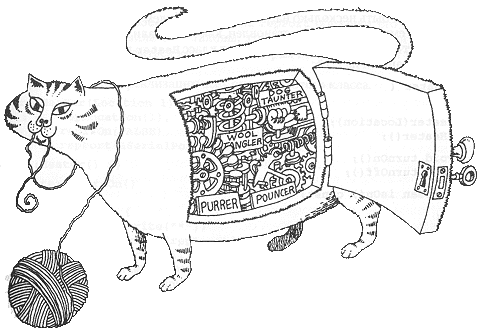 Инкапсуляция скрывает детали реализации объекта.
Инкапсуляция скрывает детали реализации объекта.
Итак, инкапсуляцию можно определить следующим образом:
Инкапсуляция - это процесс отделения друг от друга элементов объекта, определяющих его устройство и поведение; инкапсуляция служит для того, чтобы изолировать контрактные обязательства абстракции от их реализации.
Примеры инкапсуляции. Вернемся к примеру гидропонного тепличного хозяйства. Еще одной из ключевых абстракций данной предметной области является нагреватель, поддерживающий заданную температуру в помещении. Нагреватель является абстракцией низкого уровня, поэтому можно ограничиться всего тремя действиями с этим объектом: включение, выключение и запрос состояния. Нагреватель не должен отвечать за поддержание температуры, это будет поведением более высокого уровня, совместно реализуемым нагревателем, датчиком температуры и еще одним объектом. Мы говорим о поведении более высокого уровня, потому что оно основывается на простом поведении нагревателя и датчика, добавляя к ним кое-что еще, а именно гистерезис (или запаздывание), благодаря которому можно обойтись без частых включений и выключении нагревателя в состояниях, близких к граничным. Приняв такое решение о разделении ответственности, мы делаем каждую абстракцию более цельной.
Как всегда, начнем с типов.
// Булевский тип
enum Boolean {FALSE, TRUE};
В дополнение к трем предложенным выше операциям, нужны обычные мета-операции создания и уничтожения объекта (конструктор и деструктор). Поскольку в системе может быть несколько нагревателей, мы будем при создании каждого из них сообщать ему место, где он установлен, как мы делали это с классом датчиков температуры TemperatureSensor. Итак, вот класс Heater для абстрактных нагревателей, написанный на C++:
class Heater {
public:
Heater(Location);
~Heater();
void turnOn();
void tum0ff();
Boolean is0n() const;
private:
};
Вот и все, что посторонним надо знать о классе Heater. Внутренность класса это совсем другое дело. Предположим, проектировщики аппаратуры решили разместить управляющие компьютеры вне теплицы (где слишком жарко и влажно), и соединить их с датчиками и исполнительными устройствами с помощью последовательных интерфейсов. Разумно ожидать, что нагреватели будут коммутироваться с помощью блока реле, а оно будет управляться командами, поступающими через последовательный интерфейс. Скажем, для включения нагревателя передается текстовое имя команды, номер места нагревателя и еще одно число, используемое как сигнал включения нагревателя.
Вот класс, выражающий абстрактный последовательный порт.
class SerialPort {
public:
SerialPort();
~SerialPort();
void write(char*);
void write(int);
static SerialPort ports[10];
private:
};
Экземпляры этого класса будут настоящими последовательными портами, в которые можно выводить строки и числа.
Добавим еще три параметра в класс Heater.
class Heater {
public:
...
protected:
const Location repLocation;
Boolean repIsOn;
SerialPort* repPort;
};
Эти параметры repLocation, repIsOn, repPort образуют его инкапсулированное состояние. Правила C++ таковы, что при компиляции программы, если клиент попытается обратиться к этим параметрам напрямую, будет выдано сообщение об ошибке.
Определим теперь реализации всех операций этого класса.
Heater::Heater(Location 1)
: repLocation(1),
repIsOn(FALSE),
repPort(&SerialPort::ports[l]) {}
Heater::Heater() {}
void Heater::turnOn()
{
if (!repls0n) {
repPort->write("*");
repPort->write(repLocation);
repPort->write(1);
repIsOn = TRUE;
}
}
void Heater::turn0ff()
{
if (repIsOn) {
repPort->write("*");
repPort->write(repLocation);
repPort->write(0);
repIsOn = FALSE;
}
}
Boolean Heater::is0n() const
{
return repIsOn;
}
Такой стиль реализации типичен для хорошо структурированных объектно-ориентированных систем: классы записываются экономно, поскольку их специализация осуществляется через подклассы.
Предположим, что по какой-либо причине изменилась архитектура аппаратных средств системы и вместо последовательного порта управление должно осуществляться через фиксированную область памяти. Нет необходимости изменять интерфейсную часть класса - достаточно переписать реализацию. Согласно правилам C++, после этого придется перекомпилировать измененный класс, но не другие объекты, если только они не зависят от временных и пространственных характеристик прежнего кода (что крайне нежелательно и совершенно не нужно).
Обратимся теперь к реализации класса GrowingPlan. Как было сказано, это, в сущности, временной график действий. Вероятно, лучшей реализацией его был бы словарь пар время-действие с открытой хеш-таблицей. Нет смысла запоминать действия час за часом, они происходят не так часто, а в промежутках между ними система может интерполировать ход процесса.
Инкапсуляция скроет от посторонних взглядов два секрета: то, что в действительности график использует открытую хеш-таблицу, и то, что промежуточные значения интерполируются. Клиенты вольны думать, что они получают данные из почасового массива значений параметров.
Разумная инкапсуляция локализует те особенности проекта, которые могут подвергнуться изменениям. По мере развития системы разработчики могут решить, что какие-то операции выполняются несколько дольше, чем допустимо, а какие-то объекты занимают больше памяти, чем приемлемо. В таких ситуациях часто изменяют внутреннее представление объекта, чтобы реализовать более эффективные алгоритмы или оптимизировать алгоритм по критерию памяти, заменяя хранение данных вычислением. Важным преимуществом ограничения доступа является возможность внесения изменений в объект без изменения других объектов.
В идеальном случае попытки обращения к данным, закрытым для доступа, должны выявляться во время компиляции программы. Вопрос реализации этих условий для конкретных языков программирования является предметом постоянных обсуждений. Так, Smalltalk обеспечивает защиту от прямого доступа к экземплярам другого класса, обнаруживая такие попытки во время компиляции. В тоже время Object Pascal не инкапсулирует представление класса, так что ничто в этом языке не предохраняет клиента от прямых ссылок на внутренние поля другого объекта. Язык CLOS занимает в этом вопросе промежуточную позицию, возлагая все обязанности по ограничению доступа на программиста. В этом языке все слоты могут сопровождаться атрибутами :reader, :writer и :accessor, разрешающими соответственно чтение, запись или полный доступ к данным (то есть и чтение, и запись). При отсутствии атрибутов слот полностью инкапсулирован. По соглашению, признание того, что некоторая величина хранится в слоте, рассматривается как нарушение абстракции, так что хороший стиль программирования на CLOS требует, чтобы при публикации интерфейса класса, документировались бы только имена его функций, а тот факт, что слот имеет функции полного доступа, должен скрываться [55]. В языке C++ управление доступом и видимостью более гибко. Члены класса могут быть отнесены к открытой, закрытой или защищенной частям. Открытая часть доступна для всех объектов; закрытая часть полностью закрыта для других объектов; защищенная часть видна только экземплярам данного класса и его подклассов. Кроме того, в C++ существует понятие "друзей" (friends), для которых открыта закрытая часть.
Скрытие информации - понятие относительное: то, что спрятано на одном уровне абстракции, обнаруживается на другом уровне. Забраться внутрь объектов можно; правда, обычно требуется, чтобы разработчик класса-сервера об этом специально позаботился, а разработчики классов-клиентов не поленились в этом разобраться. Инкапсуляция не спасает от глупости; она, как отметил Страуструп, "защищает от ошибок, но не от жульничества" [56]. Разумеется, язык программирования тут вообще ни при чем; разве что операционная система может ограничить доступ к файлам, в которых описаны реализации классов. На практике же иногда просто необходимо ознакомиться с реализацией класса, чтобы понять его назначение, особенно, если нет внешней документации.
Модульность
Понятие модульности. По мнению Майерса "Разделение программы на модули до некоторой степени позволяет уменьшить ее сложность... Однако гораздо важнее тот факт, что внутри модульной программы создаются множества хорошо определенных и документированных интерфейсов. Эти интерфейсы неоценимы для исчерпывающего понимания программы в целом" [57]. В некоторых языках программирования, например в Smalltalk, модулей нет, и классы составляют единственную физическую основу декомпозиции. В других языках, включая Object Pascal, C++, Ada, CLOS, модуль - это самостоятельная языковая конструкция. В этих языках классы и объекты составляют логическую структуру системы, они помещаются в модули, образующие физическую структуру системы. Это свойство становится особенно полезным, когда система состоит из многих сотен классов.
Согласно Барбаре Лисков "модульность - это разделение программы на фрагменты, которые компилируются по отдельности, но могут устанавливать связи с другими модулями". Мы будем пользоваться определением Парнаса: "Связи между модулями - это их представления друг о друге" [58]. В большинстве языков, поддерживающих принцип модульности как самостоятельную концепцию, интерфейс модуля отделен от его реализации. Таким образом, модульность и инкапсуляция ходят рука об руку. В разных языках программирования модульность поддерживается по-разному. Например, в C++ модулями являются раздельно компилируемые файлы. Для C/C++ традиционным является помещение интерфейсной части модулей в отдельные файлы с расширением .h (так называемые файлы-заголовки). Реализация, то есть текст модуля, хранится в файлах с расширением .с (в программах на C++ часто используются расширения .ее, .ср и .срр). Связь между файлами объявляется директивой макропроцессора #include. Такой подход строится исключительно на соглашении и не является строгим требованием самого языка. В языке Object Pascal принцип модульности формализован несколько строже. В этом языке определен особый синтаксис для интерфейсной части и реализации модуля (unit). Язык Ada идет еще на шаг дальше: модуль (называемый package) также имеет две части - спецификацию и тело. Но, в отличие от Object Pascal, допускается раздельное определение связей с модулями для спецификации и тела пакета. Таким образом, допускается, чтобы тело модуля имело связи с модулями, невидимыми для его спецификации.
Правильное разделение программы на модули является почти такой же сложной задачей, как выбор правильного набора абстракций. Абсолютно прав Зельковиц, утверждая: "поскольку в начале работы над проектом решения могут быть неясными, декомпозиция на модули может вызвать затруднения. Для хорошо известных приложений (например, создание компиляторов) этот процесс можно стандартизовать, но для новых задач (военные системы или управление космическими аппаратами) задача может быть очень трудной" [59].
Модули выполняют роль физических контейнеров, в которые помещаются определения классов и объектов при логическом проектировании системы. Такая же ситуация возникает у проектировщиков бортовых компьютеров. Логика электронного оборудования может быть построена на основе элементарных схем типа НЕ, И-НЕ, ИЛИ-НЕ, но можно объединить такие схемы в стандартные интегральные схемы (модули), например, серий 7400, 7402 или 7404.
Для небольших задач допустимо описание всех классов и объектов в одном модуле. Однако для большинства программ (кроме самых тривиальных) лучшим решением будет сгруппировать в отдельный модуль логически связанные классы и объекты, оставив открытыми те элементы, которые совершенно необходимо видеть другим модулям. Такой способ разбиения на модули хорош, но его можно довести до абсурда. Рассмотрим, например, задачу, которая выполняется на многопроцессорном оборудовании и требует для координации своей работы механизм передачи сообщений. В больших системах, подобных описываемым в главе 12, вполне обычным является наличие нескольких сотен и даже тысяч видов сообщений. Было бы наивным определять каждый класс сообщения в отдельном модуле. При этом не только возникает кошмар с документированием, но даже просто поиск нужных фрагментов описания становится чрезвычайно труден для пользователя. При внесении в проект изменений потребуется модифицировать и перекомпилировать сотни модулей. Этот пример показывает, что скрытие информации имеет и обратную сторону [60]. Деление программы на модули бессистемным образом иногда гораздо хуже, чем отсутствие модульности вообще.
 Модульность позволяет хранить абстракции раздельно.
Модульность позволяет хранить абстракции раздельно.
В традиционном структурном проектировании модульность - это искусство раскладывать подпрограммы по кучкам так, чтобы в одну кучку попадали подпрограммы, использующие друг друга или изменяемые вместе. В объектно-ориентированном программировании ситуация несколько иная: необходимо физически разделить классы и объекты, составляющие логическую структуру проекта.
На основе имеющегося опыта можно перечислить приемы и правила, которые позволяют составлять модули из классов и объектов наиболее эффективным образом. Бритон и Парнас считают, что "конечной целью декомпозиции программы на модули является снижение затрат на программирование за счет независимой разработки и тестирования. Структура модуля должна быть достаточно простой для восприятия; реализация каждого модуля не должна зависеть от реализации других модулей; должны быть приняты меры для облегчения процесса внесения изменений там, где они наиболее вероятны" [61]. Прагматические соображения ставят предел этим руководящим указаниям. На практике перекомпиляция тела модуля не является трудоемкой операцией: заново компилируется только данный модуль, и программа перекомпонуется. Перекомпиляция интерфейсной части модуля, напротив, более трудоемка. В строго типизированных языках приходится перекомпилировать интерфейс и тело самого измененного модуля, затем все модули, связанные с данным, модули, связанные с ними, и так далее по цепочке. В итоге для очень больших программ могут потребоваться многие часы на перекомпиляцию (если только среда разработки не поддерживает фрагментарную компиляцию), что явно нежелательно. Поэтому следует стремиться к тому, чтобы интерфейсная часть модулей была возможно более узкой (в пределах обеспечения необходимых связей). Наш стиль программирования требует скрыть все, что только возможно, в реализации модуля. Постепенный перенос описаний из реализации в интерфейсную часть гораздо менее опасен, чем "вычищение" избыточного интерфейсного кода.
Таким образом, программист должен находить баланс между двумя противоположными тенденциями: стремлением скрыть информацию и необходимостью обеспечения видимости тех или иных абстракций в нескольких модулях. Парнас, Клеменс и Вейс предложили следующее правило: "Особенности системы, подверженные изменениям, следует скрывать в отдельных модулях; в качестве межмодульных можно использовать только те элементы, вероятность изменения которых мала. Все структуры данных должны быть обособлены в модуле; доступ к ним будет возможен для всех процедур этого модуля и закрыт для всех других. Доступ к данным из модуля должен осуществляться только через процедуры данного модуля" [62]. Другими словами, следует стремиться построить модули так, чтобы объединить логически связанные абстракции и минимизировать взаимные связи между модулями. Исходя из этого, приведем определение модульности:
Модульность - это свойство системы, которая была разложена на внутренне связные, но слабо связанные между собой модули.
Таким образом, принципы абстрагирования, инкапсуляции и модульности являются взаимодополняющими. Объект логически определяет границы определенной абстракции, а инкапсуляция и модульность делают их физически незыблемыми.
В процессе разделения системы на модули могут быть полезными два правила. Во-первых, поскольку модули служат в качестве элементарных и неделимых блоков программы, которые могут использоваться в системе повторно, распределение классов и объектов по модулям должно учитывать это. Во-вторых, многие компиляторы создают отдельный сегмент кода для каждого модуля. Поэтому могут появиться ограничения на размер модуля. Динамика вызовов подпрограмм и расположение описаний внутри модулей может сильно повлиять на локальность ссылок и на управление страницами виртуальной памяти. При плохом разбиении процедур по модулям учащаются взаимные вызовы между сегментами, что приводит к потере эффективности кэш-памяти и частой смене страниц.
На выбор разбиения на модули могут влиять и некоторые внешние обстоятельства. При коллективной разработке программ распределение работы осуществляется, как правило, по модульному принципу и правильное разделение проекта минимизирует связи между участниками. При этом более опытные программисты обычно отвечают за интерфейс модулей, а менее опытные - за реализацию. На более крупном уровне такие же соотношения справедливы для отношений между субподрядчиками. Абстракции можно распределить так, чтобы быстро установить интерфейсы модулей по соглашению между компаниями, участвующими в работе. Изменения в интерфейсе вызывают много крика и зубовного скрежета, не говоря уже об огромном расходе бумаги, - все эти факторы делают интерфейс крайне консервативным. Что касается документирования проекта, то оно строится, как правило, также по модульному принципу - модуль служит единицей описания и администрирования. Десять модулей вместо одного потребуют в десять раз больше описаний, и поэтому, к сожалению, иногда требования по документированию влияют на декомпозицию проекта (в большинстве случаев негативно). Могут сказываться и требования секретности: часть кода может быть несекретной, а другая - секретной; последняя тогда выполняется в виде отдельного модуля (модулей).
Свести воедино столь разноречивые требования довольно трудно, но главное уяснить: вычленение классов и объектов в проекте и организация модульной структуры - независимые действия. Процесс вычленения классов и объектов составляет часть процесса логического проектирования системы, а деление на модули - этап физического проектирования. Разумеется, иногда невозможно завершить логическое проектирование системы, не завершив физическое проектирование, и наоборот. Два этих процесса выполняются итеративно.
Примеры модульности. Посмотрим, как реализуется модульность в гидропонной огородной системе. Допустим, вместо закупки специализированного аппаратного обеспечения, решено использовать стандартную рабочую станцию с графическим интерфейсом пользователя GUI (Graphical User Interface). С помощью рабочей станции оператор может формировать новые планы выращивания, модифицировать имеющиеся планы и наблюдать за их исполнением. Так как абстракция плана выращивания - одна из ключевых, создадим модуль, содержащий все, относящееся к плану выращивания. На C++ нам понадобится примерно такой файл-заголовок (пусть он называется gplan.h).
// gplan.h
#ifndef _GPLAN_H
#define _GPLAN_H 1
#include "gtypes.h"
#include "except.h"
#include "actions.h"
class GrowingPlan ...
class FruitGrowingPlan ...
class GrainGrowingPlan ...
#endif
Здесь мы импортируем в файл три других заголовочных файла с определением интерфейсов, на которые будем ссылаться: gtypes.h, except .h и actions.h. Собственно код классов мы поместим в модуль реализации, в файл с именем gplan.cpp.
Мы могли бы также собрать в один модуль все программы, относящиеся к окнам диалога, специфичным для данного приложения. Этот модуль наверняка будет зависеть от классов, объявленных в gplan.h, и от других файлов-заголовков с описанием классов GUI.
Вероятно, будет много других модулей, импортирующих интерфейсы более низкого уровня. Наконец мы доберемся до главной функции - точки запуска нашей программы операционной системой. При объектно-ориентированном проектировании это скорее всего будет самая малозначительная и неинтересная часть системы, в то время, как в традиционном структурном подходе головная функция - это краеугольный камень, который держит все сооружение. Мы полагаем, что объектно-ориентированный подход более естественен, поскольку, как замечает Мейер, "на практике программные системы предлагают некоторый набор услуг. Сводить их к одной функции можно, но противоестественно... Настоящие системы не имеют верхнего уровня" [63].
Иерархия
Что такое иерархия? Абстракция - вещь полезная, но всегда, кроме самых простых ситуаций, число абстракций в системе намного превышает наши умственные возможности. Инкапсуляция позволяет в какой-то степени устранить это препятствие, убрав из поля зрения внутреннее содержание абстракций. Модульность также упрощает задачу, объединяя логически связанные абстракции в группы. Но этого оказывается недостаточно.
Значительное упрощение в понимании сложных задач достигается за счет образования из абстракций иерархической структуры. Определим иерархию следующим образом:
Иерархия - это упорядочение абстракций, расположение их по уровням.
Основными видами иерархических структур применительно к сложным системам являются структура классов (иерархия "is-a") и структура объектов (иерархия "part of").
Примеры иерархии: одиночное наследование. Важным элементом объектно-ориентированных систем и основным видом иерархии "is-a" является упоминавшаяся выше концепция наследования. Наследование означает такое отношение между классами (отношение родитель/потомок), когда один класс заимствует структурную или функциональную часть одного или нескольких других классов (соответственно, одиночное и множественное наследование). Иными словами, наследование создает такую иерархию абстракций, в которой подклассы наследуют строение от одного или нескольких суперклассов. Часто подкласс достраивает или переписывает компоненты вышестоящего класса.
Семантически, наследование описывает отношение типа "is-a". Например, медведь есть млекопитающее, дом есть недвижимость и "быстрая сортировка" есть сортирующий алгоритм. Таким образом, наследование порождает иерархию "обобщение-специализация", в которой подкласс представляет собой специализированный частный случай своего суперкласса. "Лакмусовая бумажка" наследования - обратная проверка; так, если B не есть A, то B не стоит производить от A.
Рассмотрим теперь различные виды растений, выращиваемых в нашей огородной системе. Мы уже ввели обобщенное представление абстрактного плана выращивания растений. Однако разные культуры требуют разных планов. При этом планы для фруктов похожи друг на друга, но отличаются от планов для овощей или цветов. Имеет смысл ввести на новом уровне абстракции обобщенный "фруктовый" план, включающий указания по опылению и сборке урожая. Вот как будет выглядеть на C++ определение плана для фруктов, как наследника общего плана выращивания.
// Тип Урожай
typedef unsigned int Yield;
class FruitGrowingPlan : public
GrowingPlan {
public:
FruitGrowingPlan(char*
name);
virtual ~FruitGrowingPlan();
virtual void establish(Day, Hour,
Condition&);
void scheduleHarvest(Day, Hour);
Boolean isHarvested() const;
unsigned daysUntilHarvest() const;
Yield estimatedYield() const;
protected:
Boolean repHarvested;
Yield repYield;
 Абстракции образуют иерархию.
Абстракции образуют иерархию.
Это означает, что план выращивания фруктов FruitGrowingPlan является разновидностью плана выращивания GrowingPlan. В него добавлены параметры repHarvested и repYield, определены четыре новые функции и переопределена функция establish. Теперь мы могли бы продолжить специализацию - например, определить на базе "фруктового" плана "яблочный" класс AppleGrowingPlan.
В наследственной иерархии общая часть структуры и поведения сосредоточена в наиболее общем суперклассе. По этой причине говорят о наследовании, как об иерархии обобщение-специализация. Суперклассы при этом отражают наиболее общие, а подклассы - более специализированные абстракции, в которых члены суперкласса могут быть дополнены, модифицированы и даже скрыты. Принцип наследования позволяет упростить выражение абстракций, делает проект менее громоздким и более выразительным. Кокс пишет: "В отсутствие наследования каждый класс становится самостоятельным блоком и должен разрабатываться "с нуля". Классы лишаются общности, поскольку каждый программист реализует их по-своему. Стройность системы достигается тогда только за счет дисциплинированности программистов. Наследование позволяет вводить в обращение новые программы, как мы обучаем новичков новым понятиям - сравнивая новое с чем-то уже известным" [64].
Принципы абстрагирования, инкапсуляции и иерархии находятся между собой в некоем здоровом конфликте. Данфорт и Томлинсон утверждают: "Абстрагирование данных создает непрозрачный барьер, скрывающий состояние и функции объекта; принцип наследования требует открыть доступ и к состоянию, и к функциям объекта для производных объектов" [65]. Для любого класса обычно существуют два вида клиентов: объекты, которые манипулируют с экземплярами данного класса, и подклассы-наследники. Лисков поэтому отмечает, что существуют три способа нарушения инкапсуляции через наследование: "подкласс может получить доступ к переменным экземпляра своего суперкласса, вызвать закрытую функцию и, наконец, обратиться напрямую к суперклассу своего суперкласса" [66]. Различные языки программирования по-разному находят компромисс между наследованием и инкапсуляцией; наиболее гибким в этом отношении является C++. В нем интерфейс класса может быть разделен на три части: закрытую (private), видимую только для самого класса; защищенную (protected), видимую также и для подклассов; и открытую (public), видимую для всех.
Примеры иерархии: множественное наследование. В предыдущем примере рассматривалось одиночное наследование, когда подкласс FruitGrowingPlan был создан только из одного суперкласса GrowingPlan. В ряде случаев полезно реализовать наследование от нескольких суперклассов. Предположим, что нужно определить класс, представляющий разновидности растений.
class Plant {
public:
Plant(char* name, char* species);
virtual ~Plant();
void setDatePlanted(Day);
virtual establishGrowingConditions(const Condition&);
const char* name() const;
const char* species() const;
Day datePlantedt) const;
protected:
char* repName;
char* repSpecies;
Day repPlanted;
private:
...
};
Каждый экземпляр класса plant будет содержать имя, вид и дату посадки. Кроме того, для каждого вида растений можно задавать особые оптимальные условия выращивания. Мы хотим, чтобы эта функция переопределялась подклассами, поэтому она объявлена виртуальной при реализации в C++. Три параметра объявлены как защищенные, то есть они будут доступны и классу, и подклассам (закрытая часть спецификации доступна только самому классу).
Изучая предметную область, мы приходим к выводу, что различные группы культивируемых растений - цветы, фрукты и овощи, - имеют свои особые свойства, существенные для технологии их выращивания. Например, для цветов важно знать времена цветения и созревания семян. Аналогично, время сбора урожая важно для абстракций фруктов и овощей. Создадим два новых класса - цветы (Flower) и фрукты-овощи (FruitVegetable); они оба наследуют от класса Plant. Однако некоторые цветочные растения имеют плоды! Для этой абстракции придется создать третий класс, FlowerFruitVegetable, который будет наследовать от классов Flower и FruitVegetablePlant.
Чтобы не было избыточности, в данном случае очень пригодится множественное наследование. Сначала давайте опишем отдельно цветы и фрукты-овощи.
class FlowerMixin {
public:
FlowerMixin(Day timeToFlower, Day timeToSeed);
virtual ~FlowerMixin();
Day timeToFlower() const;
Day timeToSeed() const;
protected:
...
};
class FruitVegetableMixin {
public:
FruitVegetableMixin(Day timeToHarvest);
virtual ~FruitVegetableMixin();
Day timeToHarvest() const;
protected:
...
};
Мы намеренно описали эти два класса без наследования. Они ни от кого не наследуют и специально предназначены для того, чтобы их подмешивали (откуда и имя Mixin) к другим классам. Например, опишем розу:
class Rose : public Plant, public FlowerMixin...
А вот морковь:
class Carrot : public Plant, public FruiteVegetableMixin {};
В обоих случаях классы наследуют от двух суперклассов: экземпляры подкласса Rose включают структуру и поведение как из класса Plant, так и из класса FlowerMixin. И вот теперь определим вишню, у которой товаром являются как цветы, так и плоды:
class Cherry : public Plant, public FlowerMixin, FruitVegetableMixin...
Множественное наследование - вещь нехитрая, но оно осложняет реализацию языков программирования. Есть две проблемы - конфликты имен между различными суперклассами и повторное наследование. Первый случай, это когда в двух или большем числе суперклассов определено поле или операция с одинаковым именем. В C++ этот вид конфликта должен быть явно разрешен вручную, а в Smalltalk берется то, которое встречается первым. Повторное наследование, это когда класс наследует двум классам, а они порознь наследуют одному и тому же четвертому. Получается ромбическая структура наследования и надо решить, должен ли самый нижний класс получить одну или две отдельные копии самого верхнего класса? В некоторых языках повторное наследование запрещено, в других конфликт решается "волевым порядком", а в C++ это оставляется на усмотрение программиста. Виртуальные базовые классы используются для запрещения дублирования повторяющихся структур, в противном случае в подклассе появятся копии полей и функций и потребуется явное указание происхождения каждой из копий.
Множественным наследованием часто злоупотребляют. Например, сладкая вата - это частный случай сладости, но никак не ваты. Применяйте ту же "лакмусовую бумажку": если B не есть A, то ему не стоит наследовать от A. Часто плохо сформированные структуры множественного наследования могут быть сведены к единственному суперклассу плюс агрегация других классов подклассом.
Примеры иерархии: агрегация. Если иерархия "is а" определяет отношение "обобщение/специализация", то отношение "part of" (часть) вводит иерархию агрегации. Вот пример.
class Garden {
public:
Garden();
virtual ~Garden();
protected:
Plant* repPlants[100];
GrowingPlan repPlan;
};
Это - абстракция огорода, состоящая из массива растений и плана выращивания.
Имея дело с такими иерархиями, мы часто говорим об уровнях абстракции, которые впервые предложил Дейкстра [67]. В иерархии классов вышестоящая абстракция является обобщением, а нижестоящая - специализацией. Поэтому мы говорим, что класс Flower находится на более высоком уровне абстракции, чем класс Plant. В иерархии "part of" класс находится на более высоком уровне абстракции, чем любой из использовавшихся при его реализации. Так класс Garden стоит на более высоком уровне, чем класс Plant.
Агрегация есть во всех языках, использующих структуры или записи, состоящие из разнотипных данных. Но в объектно-ориентированном программировании она обретает новую мощь: агрегация позволяет физически сгруппировать логически связанные структуры, а наследование с легкостью копирует эти общие группы в различные абстракции.
В связи с агрегацией возникает проблема владения, или принадлежности объектов. В нашем абстрактном огороде одновременно растет много растений, и от удаления или замены одного из них огород не становится другим огородом. Если мы уничтожаем огород, растения остаются (их ведь можно пересадить). Другими словами, огород и растения имеют свои отдельные и независимые сроки жизни; мы достигли этого благодаря тому, что огород содержит не сами объекты Plant, а указатели на них. Напротив, мы решили, что объект GrowingPlan внутренне связан с объектом Garden и не существует независимо. План выращивания физически содержится в каждом экземпляре огорода и погибает вместе с ним. Подробнее про семантику владения мы будем говорить в следующей главе.
Типизация
Что такое типизация? Понятие типа взято из теории абстрактных типов данных. Дойч определяет тип, как "точную характеристику свойств, включая структуру и поведение, относящуюся к некоторой совокупности объектов" [68]. Для наших целей достаточно считать, что термины тип и класс взаимозаменяемы [Тип и класс не вполне одно и то же; в некоторых языках их различают. Например, ранние версии языка Trellis/Owl разрешали объекту иметь и класс, и тип. Даже в Smalltalk объекты классов SmallInteger, LargeNegativeInteger, LargePositiveInteger относятся к одному типу Integer, хотя и к разным классам [69]. Большинству смертных различать типы и классы просто противно и бесполезно. Достаточно сказать, что класс реализует понятие типа]. Тем не менее, типы стоит обсудить отдельно, поскольку они выставляют смысл абстрагирования в совершенно другом свете. В частности, мы утверждаем, что:
Типизация - это способ защититься от использования объектов одного класса вместо другого, или по крайней мере управлять таким использованием.
Типизация заставляет нас выражать наши абстракции так, чтобы язык программирования, используемый в реализации, поддерживал соблюдение принятых проектных решений. Вегнер замечает, что такой способ контроля существенен для программирования "в большом" [70].
Идея согласования типов занимает в понятии типизации центральное место. Например, возьмем физические единицы измерения [71]. Деля расстояние на время, мы ожидаем получить скорость, а не вес. В умножении температуры на силу смысла нет, а в умножении расстояния на силу - есть. Все это примеры сильной типизации, когда прикладная область накладывает правила и ограничения на использование и сочетание абстракций.
Примеры сильной и слабой типизации. Конкретный язык программирования может иметь сильный или слабый механизм типизации, и даже не иметь вообще никакого, оставаясь объектно-ориентированным. Например, в Eiffel соблюдение правил использования типов контролируется непреклонно, - операция не может быть применена к объекту, если она не зарегистрирована в его классе или суперклассе. В сильно типизированных языках нарушение согласования типов может быть обнаружено во время трансляции программы. С другой стороны, в Smalltalk типов нет: во время исполнения любое сообщение можно послать любому объекту, и если класс объекта (или его надкласс) не понимает сообщение, то генерируется сообщение об ошибке. Нарушение согласования типов может не обнаружиться во время трансляции и обычно проявляется как ошибка исполнения. C++ тяготеет к сильной типизации, но в этом языке правила типизации можно игнорировать или подавить полностью.
Рассмотрим абстракцию различных типов емкостей, которые могут использоваться в нашей теплице. Вероятно, в ней есть емкости для воды и для минеральных удобрений; хотя первые предназначены для жидкостей, а вторые для сыпучих веществ, они имеют достаточно много общего, чтобы устроить иерархию классов. Начнем с типов.
// Число, обозначающее уровень от 0 до 100 процентов
typedef float Level;
Операторы typedef в C++ не вводят новых типов. В частности, и Level и Concentration - на самом деле другие названия для float, и их можно свободно смешивать в вычислениях. В этом смысле C++ имеет слабую типизацию: значения примитивных типов, таких, как int или float неразличимы в пределах данного типа. Напротив, Ada и Object Pascal предоставляют сильную типизацию для примитивных типов. В Ada можно объявить самостоятельным типом интервал значений или подмножество с ограниченной точностью.
 Строгая типизация предотвращает смешивание абстракций.
Строгая типизация предотвращает смешивание абстракций.
Построим теперь иерархию классов для емкостей:
class StorageTank {
public:
StorageTank();
virtual ~StorageTank();
virtual void fill();
virtual void startDraining();
virtual void stopDraining();
Boolean isEmpty() const;
Level level() const;
protected:
...
};
class WaterTank : public StorageTank{
public:
WaterTank();
virtual ~WaterTank();
virtual void fill();
virtual void startDraining();
virtual void stopDraining();
void startHeating();
void stopHeating();
Temperature currentTemperature()
const;
protected:
...
};
class NutrientTank : public StorageTank
{
public:
NutrientTank();
virtual ~NutrientTank();
virtual void startDrainingt();
virtual void stopDraining();
protected:
...
};
Класс StorageTank - это базовый класс иерархии. Он обеспечивает структуру и поведение общие для всех емкостей: возможность их наполнять или опустошать. Классы WaterTank (емкость для воды) и NutrientTank (для удобрений) наследуют свойства StorageTank, частично переопределяют их и добавляют кое-что свое: например, класс WaterTank вводит новое поведение, связанное с температурой.
Предположим, что мы имеем
следующие описания:
StorageTank s1, s2;
WaterTank w;
NutrientTank n;
Заметьте, переменные такие как s1, s2, w или n - это не экземпляры соответствующих классов. На самом деле, это просто имена, которыми мы обозначаем объекты соответствующих классов: когда мы говорим "объект s1" мы на самом деле имеем ввиду экземпляр StorageTank, обозначаемый переменной s1. Мы вернемся к этому тонкому вопросу в следующей главе.
При проверке типов у классов, C++ типизирован гораздо строже. Под этим понимается, что выражения, содержащие вызовы операций, проверяются на согласование типов во время компиляции. Например, следующее правильно:
Level l = s1.level();
w.startDrainingt();
n.stopDraining();
Действительно, такие селекторы есть в классах, к которым принадлежат соответствующие переменные. Напротив, следующее неправильно и вызовет ошибку компиляции:
s1.startHeating(); // Неправильно
n.stopHeating(); // Неправильно
Таких функций нет ни в самих классах, ни в их суперклассах. Но следующее
n.fill();
совершенно правильно: функции fill нет в определении NutrientTank, но она есть в вышестоящем классе.
Итак, сильная типизация заставляет нас соблюдать правила использования абстракций, поэтому она тем полезнее, чем больше проект. Однако у нее есть и теневая сторона. А именно, даже небольшие изменения в интерфейсе класса требуют перекомпиляции всех его подклассов. Кроме того, не имея параметризованных классов, о которых речь пойдет в главах 3 и 9, трудно представить себе, как можно было бы создать собрание разнородных объектов. Предположим, что мы хотим ввести абстракцию инвентарного списка, в котором собирается все имущество, связанное с теплицей. Обычная для С идиома применима и в C++: нужно использовать класс-контейнер, содержащий указатели на void, то есть на объекты произвольного типа.
class Inventory {
public:
Inventory();
~Inventory();
void add(void*);
void remove(void*);
void* mostRecent() const;
void apply(Boolean (*)(void*));
private:
...
};
Операция apply - это так называемый итератор, который позволяет применить какую-либо операцию ко всем объектам в списке. Подробнее об итераторах см. в следующей главе.
Имея экземпляр класса Inventory, мы можем добавлять и уничтожать указатели на объекты любых классов. Но эти действия не безопасны с точки зрения типов - в списке могут оказаться как осязаемые объекты (емкости), так и неосязаемые (температура или план выращивания), что нарушает нашу абстракцию материального учета. Более того, мы могли бы внести в список объекты классов WaterTank и TemperatureSensor, и по неосторожности ожидая от функции mostRecent объекта класса WaterTank получить StorageTank.
Вообще говоря, у этой проблемы есть два общих решения. Во-первых, можно сделать контейнерный класс, безопасный с точки зрения типов. Чтобы не манипулировать с нетипизированными указателями void, мы могли бы определить инвентаризационный класс, который манипулирует только с объектами класса TangibleAsset (осязаемого имущества), а этот класс будет подмешиваться ко всем классам, такое имущество представляющим, например, к WaterTank, но не к GrowingPlan. Тем самым можно отсечь проблему первого рода, когда неправомочно смешиваются объекты разных типов. Во-вторых, можно ввести проверку типов в ходе выполнения, для того, чтобы знать, с объектом какого типа мы имеем дело в данный момент. Например, в Smalltalk можно запрашивать у объектов их класс. В C++ такая возможность не входила в стандарт до недавнего времени, хотя на практике, конечно, можно ввести в базовый класс операцию, возвращающую код класса (строку или значение перечислимого типа). Однако для этого надо иметь очень серьезные причины, поскольку проверка типа в ходе выполнения ослабляет инкапсуляцию. Как будет показано в следующем разделе, необходимость проверки типа можно смягчить, используя полиморфные операции.
В языках с сильной типизацией гарантируется, что все выражения будут согласованы по типу. Что это значит, лучше пояснить на примере. Следующие присваивания допустимы:
s1 = s2;
s1 = w;
Первое присваивание допустимо, поскольку переменные имеют один и тот же класс, а второе - поскольку присваивание идет снизу вверх по типам. Однако во втором случае происходит потеря информации (известная в C++ как "проблема срезки"), так как класс переменной w, WaterTank, семантически богаче, чем класс переменной s1, то есть StorageTank.
Следующие присваивания неправильны:
w = s1; // Неправильно
w = n; // Неправильно
В первом случае неправильность в том, что присваивание идет сверху вниз по иерархии, а во втором классы даже не находятся в состоянии подчиненности.
Иногда необходимо преобразовать типы. Например, посмотрите на следующую функцию:
void checkLevel(const StorageTank& s);
Мы можем привести значение вышестоящего класса к подклассу в том и только в том случае, если фактическим параметром при вызове оказался объект класса WaterTank. Или вот еще случай:
if (((WaterTank&)s).currentTemperature() < 32.0) ...
Это выражение согласовано по типам, но не безопасно. Если при выполнении программы вдруг окажется, что переменная s обозначала объект класса NutrientTank, приведение типа даст непредсказуемый результат во время исполнения. Вообще говоря, преобразований типа надо избегать, поскольку они часто представляют собой нарушение принятой системы абстракций.
Теслер отметил следующие важные преимущества строго типизированных языков:
-
"Отсутствие контроля типов может приводить к загадочным сбоям в программах во время их выполнения.
-
В большинстве систем процесс редактирование-компиляция-отладка утомителен, и раннее обнаружение ошибок просто незаменимо.
-
Объявление типов улучшает документирование программ.
-
Многие компиляторы генерируют более эффективный объектный код, если им явно известны типы" [72].
Языки, в которых типизация отсутствует, обладают большей гибкостью, но даже в таких языках, по мнению Борнинга и Ингалса: "Программисты обычно знают, какие объекты ожидаются в качестве аргументов и какие будут возвращаться" [73]. На практике, особенно при программировании "в большом", надежность языков со строгой типизацией с лихвой компенсирует некоторую потерю в гибкости по сравнению с нетипизированными языками.
Примеры типизации: статическое и динамическое связывание. Сильная и статическая типизация - разные вещи. Строгая типизация следит за соответствием типов, а статическая типизация (иначе называемая статическим или ранним связыванием) определяет время, когда имена связываются с типами. Статическая связь означает, что типы всех переменных и выражений известны во время компиляции; динамическое связывание (называемое также поздним связыванием) означает, что типы неизвестны до момента выполнения программы. Концепции типизации и связывания являются независимыми, поэтому в языке программирования может быть: типизация - сильная, связывание - статическое (Ada), типизация - сильная, связывание - динамическое (C++, Object Pascal), или и типов нет, и связывание динамическое (Smalltalk). Язык CLOS занимает промежуточное положение между C++ и Smalltalk: определения типов, сделанные программистом, могут быть либо приняты во внимание, либо не приняты.
Прокомментируем это понятие снова примером на C++. Вот "свободная", то есть не входящая в определение какого-либо класса, функция [Свободная функция - функция, не входящая ни в какой класс. В чисто объектно-ориентированных языках, типа Smalltalk, свободных процедур не бывает, каждая операция связана с каким-нибудь классом]:
void balanceLevels(StorageTank& s1, StorageTank& s2);
Вызов этой функции с экземплярами класса StorageTank или любых его подклассов в качестве параметров будет согласован по типам, поскольку тип каждого фактического параметра происходит в иерархии наследования от базового класса StorageTank.
При реализации этой функции мы можем иметь что-нибудь вроде:
if (s1.level()> s2.level()) s2.fill();
В чем особенность семантики при использовании селектора level? Он определен только в классе StorageTank, поэтому, независимо от классов объектов, обозначаемых переменными в момент выполнения, будет использована одна и та же унаследованная ими функция. Вызов этой функции статически связан при компиляции - мы точно знаем, какая операция будет запущена.
Иное дело fill. Этот селектор определен в StorageTank и переопределен в WaterTank, поэтому его придется связывать динамически. Если при выполнении переменная s2 будет класса WaterTank, то функция будет взята из этого класса, а если - NutrientTank, то из StorageTank. В C++ есть специальный синтаксис для явного указания источника; в нашем примере вызов fill будет разрешен, соответственно, как WaterTank::fill или StorageTank::fill [Так синтаксис C++ определяет явную квалификацию имени].
Это особенность называется полиморфизмом: одно и то же имя может означать объекты разных типов, но, имея общего предка, все они имеют и общее подмножество операций, которые можно над ними выполнять [74]. Противоположность полиморфизму называется мономорфизмом; он характерен для языков с сильной типизацией и статическим связыванием (Ada).
Полиморфизм возникает там, где взаимодействуют наследование и динамическое связывание. Это одно из самых привлекательных свойств объектно-ориентированных языков (после поддержки абстракции), отличающее их от традиционных языков с абстрактными типами данных. И, как мы увидим в следующих главах, полиморфизм играет очень важную роль в объектно-ориентированном проектировании.
Параллелизм
Что такое параллелизм? Есть задачи, в которых автоматические системы должны обрабатывать много событий одновременно. В других случаях потребность в вычислительной мощности превышает ресурсы одного процессора. В каждой из таких ситуаций естественно использовать несколько компьютеров для решения задачи или задействовать многозадачность на многопроцессорном компьютере. Процесс (поток управления) - это фундаментальная единица действия в системе. Каждая программа имеет по крайней мере один поток управления, параллельная система имеет много таких потоков: век одних недолог, а другие живут в течении всего сеанса работы системы. Реальная параллельность достигается только на многопроцессорных системах, а системы с одним процессором имитируют параллельность за счет алгоритмов разделения времени.
Кроме этого "аппаратного" различия, мы будем различать "тяжелую" и "легкую" параллельность по потребности в ресурсах. "Тяжелые" процессы управляются операционной системой независимо от других, и под них выделяется отдельное защищенное адресное пространство. "Легкие" сосуществуют в одном адресном пространстве. "Тяжелые" процессы общаются друг с другом через операционную систему, что обычно медленно и накладно. Связь "легких" процессов осуществляется гораздо проще, часто они используют одни и те же данные.
Многие современные операционные системы предусматривают прямую поддержку параллелизма, и это обстоятельство очень благоприятно сказывается на возможности обеспечения параллелизма в объектно-ориентированных системах. Например, системы UNIX предусматривают системный вызов fork, который порождает новый процесс. Системы Windows NT и OS/2 - многопоточные; кроме того они обеспечивают программные интерфейсы для создания процессов и манипулирования с ними.
Лим и Джонсон отмечают, что "возможности проектирования параллельности в объектно-ориентированных языках не сильно отличаются от любых других, - на нижних уровнях абстракции параллелизм и OOP развиваются совершенно независимо. С OOP или без, все традиционные проблемы параллельного программирования сохраняются" [75]. Действительно, создавать большие программы и так непросто, а если они еще и параллельные, то надо думать о возможном простое одного из потоков, неполучении данных, взаимной блокировке и т.д.
К счастью, как отмечают те же авторы далее: "на верхних уровнях OOP упрощает параллельное программирование для рядовых разработчиков, пряча его в повторно-используемые абстракции" [76]. Блэк и др. сделали следующий вывод: "объектная модель хороша для распределенных систем, поскольку она неявно разбивает программу на (1) распределенные единицы и (2) сообщающиеся субъекты" [77].
В то время, как объектно-ориентированное программирование основано на абстракции, инкапсуляции и наследовании, параллелизм главное внимание уделяет абстрагированию и синхронизации процессов [78]. Объект есть понятие, на котором эти две точки зрения сходятся: каждый объект (полученный из абстракции реального мира) может представлять собой отдельный поток управления (абстракцию процесса). Такой объект называется активным. Для систем, построенных на основе OOD, мир может быть представлен, как совокупность взаимодействующих объектов, часть из которых является активной и выступает в роли независимых вычислительных центров. На этой основе дадим следующее определение параллелизма:
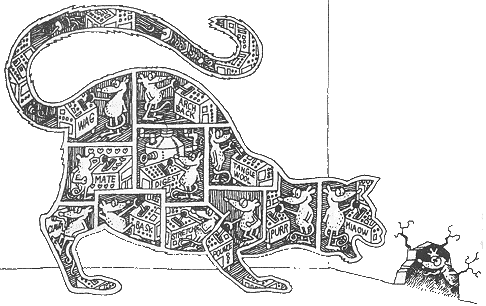 Параллелизм позволяет различным объектам действовать одновременно.
Параллелизм позволяет различным объектам действовать одновременно.
Параллелизм - это свойство, отличающее активные объекты от пассивных.
Примеры параллелизма. Ранее мы обзавелись классом ActiveTemperatureSensor, поведение которого предписывает ему периодически измерять температуру и обращаться к известной ему функции вызова, когда температура отклоняется на некоторую величину от установленного значения. Как он будет это делать, мы в тот момент не объяснили. При всех секретах реализации понятно, что это - активный объект и, следовательно, без параллелизма тут не обойтись. В объектно-ориентированном проектировании есть три подхода к параллелизму.
Во-первых, параллелизм - это внутреннее свойство некоторых языков программирования. Так, для языка Ada механизм параллельных процессов реализуется как задача. В Smalltalk есть класс process, которому наследуют все активные объекты. Есть много других языков со встроенными механизмами для параллельного выполнения и синхронизации процессов - Actors, Orient 84/K, ABCL/1, которые предусматривают сходные механизмы параллелизма и синхронизации. Во всех этих языках можно создавать активные объекты, код которых постоянно выполняется параллельно с другими активными объектами.
Во-вторых, можно использовать библиотеку классов, реализующих какую-нибудь разновидность "легкого" параллелизма. Например, библиотека AT&T для C++ содержит классы Shed, Timer, Task и т.д. Ее реализация, естественно, зависит от платформы, хотя интерфейс достаточно хорошо переносим. При этом подходе механизмы параллельного выполнения не встраиваются в язык (и, значит, не влияют на системы без параллельности), но в то же время практически воспринимаются как встроенные.
Наконец, в-третьих, можно создать иллюзию многозадачности с помощью прерываний. Для этого надо кое-что знать об аппаратуре. Например, в нашей реализации класса ActiveTemperatureSensor мы могли бы иметь аппаратный таймер, периодически прерывающий приложение, после чего все датчики измеряли бы температуру и обращались бы, если нужно, к своим функциям вызова.
Как только в систему введен параллелизм, сразу возникает вопрос о том, как синхронизировать отношения активных объектов друг с другом, а также с остальными объектами, действующими последовательно. Например, если два объекта посылают сообщения третьему, должен быть какой-то механизм, гарантирующий, что объект, на который направлено действие, не разрушится при одновременной попытке двух активных объектов изменить его состояние. В этом вопросе соединяются абстракция, инкапсуляция и параллелизм. В параллельных системах недостаточно определить поведение объекта, надо еще принять меры, гарантирующие, что он не будет растерзан на части несколькими независимыми процессами.
Сохраняемость
Любой программный объект существует в памяти и живет во времени. Аткинсон и др. предположили, что есть непрерывное множество продолжительности существования объектов: существуют объекты, которые присутствуют лишь во время вычисления выражения, но есть и такие, как базы данных, которые существуют независимо от программы. Этот спектр сохраняемости объектов охватывает:
-
"Промежуточные результаты вычисления выражений.
-
Локальные переменные в вызове процедур.
-
Собственные переменные (как в ALGOL-60), глобальные переменные
и динамически создаваемые данные.
-
Данные, сохраняющиеся между сеансами выполнения программы.
-
Данные, сохраняемые при переходе на новую версию программы.
-
Данные, которые вообще переживают программу" [79].
Традиционно, первыми тремя уровнями занимаются языки программирования, а последними - базы данных. Этот конфликт культур приводит к неожиданным решениям: программисты разрабатывают специальные схемы для сохранения объектов в период между запусками программы, а конструкторы баз данных переиначивают свою технологию под короткоживущие объекты [80].
Унификация принципов параллелизма для объектов позволила создать параллельные языки программирования. Аналогичным образом, введение сохраняемости, как нормальной составной части объектного подхода приводит нас к объектно-ориентированным базам данных (OODB, object-oriented databases). На практике подобные базы данных строятся на основе проверенных временем моделей - последовательных, индексированных, иерархических, сетевых или реляционных, но программист может ввести абстракцию объектно-ориентированного интерфейса, через который запросы к базе данных и другие операции выполняются в терминах объектов, время жизни которых превосходит время жизни отдельной программы. Как мы увидим в главе 10, эта унификация значительно упрощает разработку отдельных видов приложений, позволяя, в частности, применить единый подход к разным сегментам программы, одни из которых связаны с базами данных, а другие не имеют такой связи.
Языки программирования, как правило, не поддерживают понятия сохраняемости; примечательным исключением является Smalltalk, в котором есть протоколы для сохранения объектов на диске и загрузки с диска. Однако, записывать объекты в неструктурированные файлы - это все-таки наивный подход, пригодный только для небольших систем. Как правило, сохраняемость достигается применением (немногочисленных) коммерческих OODB [81]. Другой вариант - создать объектно-ориентированную оболочку для реляционных СУБД; это лучше, в частности, для тех, кто уже вложил средства в реляционную систему. Мы рассмотрим такую ситуацию в главе 10.
Сохраняемость - это не только проблема сохранения данных. В OODB имеет смысл сохранять и классы, так, чтобы программы могли правильно интерпретировать данные. Это создает большие трудности по мере увеличения объема данных, особенно, если класс объекта вдруг потребовалось изменить.
До сих пор мы говорили о сохранении объектов во времени. В большинстве систем объектам при их создании отводится место в памяти, которое не изменяется и в котором объект находится всю свою жизнь. Однако для распределенных систем желательно обеспечивать возможность перенесения объектов в пространстве, так, чтобы их можно было переносить с машины на машину и даже при необходимости изменять форму представления объекта в памяти. Этими вопросами мы займемся в главе 12.
В заключение определим сохраняемость следующим образом:
Сохраняемость - способность объекта существовать во времени, переживая породивший его процесс, и (или) в пространстве, перемещаясь из своего первоначального адресного пространства.
2.3. Применение объектной модели
Преимущества объектной модели
Как уже говорилось выше, объектная модель принципиально отличается от моделей, которые связаны с более традиционными методами структурного анализа, проектирования и программирования. Это не означает, что объектная модель требует отказа от всех ранее найденных и испытанных временем методов и приемов. Скорее, она вносит некоторые новые элементы, которые добавляются к предшествующему опыту. Объектный подход обеспечивает ряд существенных удобств, которые другими моделями не предусматривались. Наиболее важно, что объектный подход позволяет создавать системы, которые удовлетворяют пяти признакам хорошо структурированных сложных систем. Согласно нашему опыту, есть еще пять преимуществ, которые дает объектная модель.
Во-первых, объектная модель позволяет в полной мере использовать выразительные возможности объектных и объектно-ориентированных языков программирования. Страуструп отмечает: "Не всегда очевидно, как в полной мере использовать преимущества такого языка, как C++. Существенно повысить эффективность и качество кода можно просто за счет использования C++ в качестве "улучшенного C" с элементами абстракции данных. Однако гораздо более значительным достижением является введение иерархии классов в процессе проектирования. Именно это называется OOD и именно здесь преимущества C++ демонстрируются наилучшим образом" [82]. Опыт показал, что при использовании таких языков, как Smalltalk, Object Pascal, C++, CLOS и Ada вне объектной модели, их наиболее сильные стороны либо игнорируются, либо применяются неправильно.
 Сохраняемость поддерживает состояние и класс объекта в пространстве и во времени.
Сохраняемость поддерживает состояние и класс объекта в пространстве и во времени.
Во-вторых, использование объектного подхода существенно повышает уровень унификации разработки и пригодность для повторного использования не только программ, но и проектов, что в конце концов ведет к созданию среды разработки [83]. Объектно-ориентированные системы часто получаются более компактными, чем их не объектно-ориентированные эквиваленты. А это означает не только уменьшение объема кода программ, но и удешевление проекта за счет использования предыдущих разработок, что дает выигрыш в стоимости и времени.
В-третьих, использование объектной модели приводит к построению систем на основе стабильных промежуточных описаний, что упрощает процесс внесения изменений. Это дает системе возможность развиваться постепенно и не приводит к полной ее переработке даже в случае существенных изменений исходных требований.
В-четвертых, в главе 7 показано, как объектная модель уменьшает риск разработки сложных систем, прежде всего потому, что процесс интеграции растягивается на все время разработки, а не превращается в единовременное событие. Объектный подход состоит из ряда хорошо продуманных этапов проектирования, что также уменьшает степень риска и повышает уверенность в правильности принимаемых решений.
Наконец, объектная модель ориентирована на человеческое восприятие мира, или, по словам Робсона, "многие люди, не имеющие понятия о том, как работает компьютер, находят вполне естественным объектно-ориентированный подход к системам" [84].
Использование объектного подхода
Возможность применения объектного подхода доказана для задач самого разного характера. На рис. 2-6 приведен перечень областей, для которых реализованы объектно-ориентированные системы. Более подробные сведения об этих и других проектах можно найти в приведенной библиографии.
В настоящее время объектно-ориентированное проектирование - единственная методология, позволяющая справиться со сложностью, присущей очень большим системам. Однако, следует заметить, что иногда применение OOD может оказаться нецелесообразным, например, из-за неподготовленности персонала или отсутствия подходящих средств разработки. К этой теме мы вернемся в главе 7.
Открытые вопросы
Чтобы успешно использовать объектный подход, нам предстоит ответить на следующие вопросы:
-
Что такое классы и объекты?
-
Как идентифицировать классы и объекты в конкретных приложениях?
-
Как описать схему объектно-ориентированной системы?
-
Как создавать хорошо структурированные объектно-ориентированные системы?
-
Как организовать управление процессом разработки согласно OOD? Этим вопросам посвящены следующие пять глав.
Выводы
-
Развитие программной индустрии привело к созданию методов объектно-ориентированного анализа, проектирования и программирования, которые служат для программирования "в большом".
-
В программировании существует несколько парадигм, ориентированных на процедуры, объекты, логику, правила и ограничения.
-
Абстракция определяет существенные характеристики некоторого объекта, которые отличают его от всех других видов объектов и, таким образом, абстракция четко очерчивает концептуальную границу объекта с точки зрения наблюдателя.
-
Инкапсуляция - это процесс разделения устройства и поведения объекта; инкапсуляция служит для того, чтобы изолировать контрактные обязательства абстракции от их реализации.
| Авиационное оборудование |
Обработка коммерческой информации |
| Автоматизация учреждений |
Операционные системы |
| Автоматизированное проектирование |
Планирование инвестиций |
| Автоматизированное обучение |
Повторно используемые компоненты |
| Автоматизированное производство программного обеспечения |
Подготовка документов |
| Анимация |
Программные средства космических станций |
| Базы данных |
Проектирование интерфейса
пользователя |
| Банковское дело |
Проектирование СБИС |
| Гипермедиа |
Распознавание образов |
| Кинопроизводство |
Робототехника |
| Контроль программного обеспечения |
Системы телеметрии |
| Математический анализ |
Системы управления и регулирования |
| Медицинская электроника |
Средства разработки программ |
| Моделирование авиационной и космической техники |
Телекоммуникации |
| Музыкальная композиция |
Управление воздушным движением |
| Написание сценариев |
Управление химическими процессами |
| Нефтяная промышленность |
Экспертные системы |
Рис. 2-6. Применения объектной модели.
-
Модульность - это состояние системы, разложенной на внутренне связные и слабо связанные между собой модули.
-
Иерархия - это ранжирование или упорядочение абстракций.
-
Типизация - это способ защититься от использования объектов одного класса вместо другого, или по крайней мере способ управлять такой подменой.
-
Параллелизм - это свойство, отличающее активные объекты от пассивных.
-
Сохраняемость - способность объекта существовать во времени и (или) в пространстве.
Дополнительная литература
Концепция объектной модели была впервые введена Джонсом (Jones) [F 1979] и Вильям-сом (Williams) [F 1986]. Диссертация Кэя (Кау) [F 1969] дала направление большой части дальнейших работ по объектно-ориентированному программированию.
Шоу (Shaw) [J 1984] дала блестящий обзор механизмов абстракции в языках программирования высокого уровня. Теоретические обоснования абстракции можно найти в работах Лисков и Гуттага (Liskov and Guttag) [H 1986], Гуттага (Guttag) [J 1980] и Хилфингера Hilfinger [J 1982]. Работа Парнаса (Parnas) [F 1979] по скрытию информации была очень плодотворна. Смысл и значение иерархии обсуждается в работе под редакцией Пати (Pattee) [J 1973].
Есть масса литературы по объектно-ориентированному программированию. Карделли и Вегнер (Cardelli and Wegner) [J 1985] и Вегнер (Wegner) Х[J 1987] подготовили замечательный обзор объектных и объектно-ориентированных языков. Методические статьи Стефика и Боброва (Stefik and Bobrow) [G 1986], Страуструпа (Stroustrup) [G 1988], Hюгарта (Nygaard) [G 1986] и Грогоно (Grogono) [G 1991] полезны для начала изучения всех вопросов объектно-ориентированного программирования. В книгах Кокса (Сох) [G 1986], Мейера(Меуеr)[F 1988], Шмукера(Schmucker) [G 1986] и Кима и Лочовского (Kim and Lochovsky) [F 1989] эти же вопросы рассматриваются более подробно.
Методы объектно-ориентированного проектирования впервые ввел Буч (Booch) [F 1981, 1982, 1986, 1987, 1989]. Методы объектно-ориентированного анализа впервые ввели Шлэер и Меллор (Shiaer and Mellor) [В 1988] и Бэилин (Bailin) [В 1988]. После этого было предложено много методов объектно-ориентированного анализа и проектирования; среди них наиболее значительны были, изложенные в работах Румбаха (Rumbaugh) [F 1991], Коада и Йордона (Coad and Yourdon) [В 1991], Константайна (Constantine) [F 1989], Шлэра и Меллора (Shlaer and Mellor) [В 1992], Мартина и Одела (Martin and Odell) [В 1992], Вассермана (Wasserman) [В 1991], Джекобсона (Jacobson) [F 1992], Рубина и Голдберга (Rubin and Goldberg) [В 1992], Эмбли (Embly) [В 1992], Верфс-Брока (Wirfs-Brock) [F 1990], Голдстейна и Адлера (Goldstein and Adler) [С 1992], Хендерсон-Селлерс (Henderson-Sellers) [F 1992], Файерсмита (Firesmith) [F 1992] и Фьюжина (Fusion) [F 1992].
Разбор конкретных случаев может быть найден в работах Тэйлора (Taylor) [H 1990, С 1992], Берарда (Berard) [H 1993], Лова (Love) [С 1993] и Пинсона с Вейнером (Pinson and Weiner) [С 1990].
Замечательная подборка работ по всем аспектам объектно-ориентированной технологии может быть найдена в трудах Петерсона (Peterson) [G 1987], Шривера и Вегнера (Schriver and Wegner) [G 1987] и Хошафяна и Абнуа (Khoshafian and Abnous) [I 1990]. Труды нескольких ежегодных конференций по объектно-ориентированной технологии - это еще один богатый источник материала. Наиболее интересные форумы - OOPSLA, ЕСООР, TOOLS, Object Word и ObjectExpo.
Организации, отвечающие за стандарты по объектной технологии: Object Management Group (OMG) и комитет ANSI X3J7.
Главный источник сведений по C++ - это книга Эллис и Страуструпа (Ellis and Stroustrup) [G 1990]. Другие полезные ссылки: Страуструп (Stroustrup) [G 1991], Липпман (Lippman) I [G 1991] и Коплиен (Coplien) [1992].
|

