|
Основным преимуществом объектно-ориентированных языков программирования, таких, как C++ и Smalltalk, является высокая степень повторного использования в хорошо спроектированных системах. Это означает, что для разработки каждого следующего приложения требуется гораздо меньше нового кода; следовательно, меньшее количество кода требуется сопровождать и поддерживать.
Повторное использование принимает различные формы: заимствование отдельных строк кода, отдельных классов или логически связанных между собой групп классов. Повтор строк наиболее прост (кто из программистов хоть однажды не использовал редактор для копирования реализации того или иного алгоритма из одной программы в другую?), но наименее выгоден (один и тот же фрагмент кода просто дублируется в различных приложениях). Мы поступим гораздо лучше, используя объектно-ориентированные языки программирования и обращаясь к существующим классам, модифицируя их или наследуя от них. Но еще больших успехов можно достичь, используя наборы классов, организованные в инструментальные библиотеки, - среды разработки. Как уже отмечалось в главе 4, под средой разработки понимается совокупность классов, предоставляющих набор услуг в определенной области; таким образом, среда разработки экспортирует ряд отдельных классов и механизмов, которые клиенты могут использовать непосредственно или адаптировать.
Среды разработки могут быть достаточно универсальны и применимы к широкому кругу приложений. К этой категории относятся общие фундаментальные классы, математические библиотеки и библиотеки графического интерфейса пользователя. Среды разработки могут встречаться и в достаточно узких предметных областях, таких, например, как учет пациентов больницы, торговля текстилем, менеджмент, телефонные системы. Там, где существует семейство программ, решающих сходные задачи, появляется повод создать прикладную среду разработки.
В этой главе мы применим объектно-ориентированный подход к созданию библиотеки фундаментальных классов. В предыдущей главе нашими основными задачами были реализация управления системой в реальном времени и оптимальное разделение функциональных свойств между несколькими относительно автономными и статическими объектами. Здесь же будут доминировать два различных аспекта: стремление к гибкости архитектуры с широким выбором альтернатив оптимизации по времени и памяти, и необходимость использования общих механизмов управления памятью и синхронизацией.
9.1. Анализ
Определение границ проблемной области
На врезке представлены детально сформулированные требования к библиотеке базовых классов. К сожалению, эти требования навряд ли практически выполнимы: библиотека, содержащая абстракции, необходимые для всех возможных программ, оказалась бы слишком большой. Первой обязанностью аналитика, таким образом, является сокращение проблемной области до разумных размеров и формулировка задачи, поддающейся решению. Проблема в том виде, как она представлена сейчас, может повлечь за собой неудачу анализа в целом, поэтому необходимо сконцентрировать внимание лишь на наиболее общих абстракциях и механизмах, пригодных для широкого использования, а не пытаться сделать все для всех (что, скорее всего, приведет к созданию среды, которая никому ничего не даст). Мы начнем анализ с обзора теории структур данных и алгоритмов, а затем перейдем к абстракциям, присущим стандартному программному обеспечению.
Тем, кого интересует теоретический фундамент, можно посоветовать обратиться к плодотворной работе Кнута [2], а также других исследователей в данной области, прежде всего: Ахо, Хопкрофт и Ульман [3], Керниган и Плаугер [4], Седжуик [5], Стабс и Вебре [6], Тененбаум и Аугенстейн [7] и Вирт [8]. По мере изучения теории мы сможем определить ряд основных абстракций для нашей библиотеки, таких как очереди, стеки и графы, а также алгоритмы быстрой сортировки, сравнение с образцом, заданным регулярным выражением, и направленный поиск по дереву.
Первое открытие в ходе нашего анализа - это четкое отделение структурных абстракций (таких как очереди, стеки и графы) от алгоритмических (сортировка, сравнение с образцом и поиск). Первая категория понятий хорошо соответствует классам. Вторая категория, на первый взгляд, не поддается объектно-ориентированной декомпозиции. Однако при надлежащем подходе оказывается, что она вполне возможна: мы можем ввести классы, экземпляры которых будут агентами, выполняющими данные функции. Как будет видно далее, объективация алгоритмических абстракций обеспечивает преимущества общности, благодаря тому, что алгоритмы можно разместить в иерархии "обобщение/специализация".
Требования к библиотеке базовых классов
Библиотека должна содержать универсальные структуры данных и алгоритмы, способные удовлетворить потребности большинства стандартных приложении C++. Кроме того, библиотека должна быть:
| ® Полной |
Библиотека должна содержать семейство классов, объединенных согласованным внешним интерфейсом, но с разными представлениями, так чтобы разработчики могли выбрать то, семантика которого наиболее точно соответствует приложению. |
| ® Адаптируемой |
Все фрагменты кода, зависящие от платформы, должны быть выделены и изолированы в отдельные классы для обеспечения возможности локальных изменений в них. В частности, разработчик должен иметь контроль над механизмами хранения данных и синхронизации процессов. |
| ® Эффективной |
Процедура подключения различных фрагментов библиотеки к приложению должна быть простой (эффективность при компиляции). Непроизводительные затраты оперативной памяти и процессорного времени на обслуживание и подключение должны быть сведены к минимуму (эффективность при исполнении). Библиотека должна обеспечивать более надежную работу, чем механизмы, разработанные пользователем вручную (эффективность при разработке). |
| ® Безопасной |
Каждая абстракция должна быть безопасной с точки зрения типов, так чтобы статические предположения о поведении класса могли быть обеспечены компилятором. Для выявления нарушений динамической семантики классов должен быть использован механизм исключений. Возбуждение исключения не должно испортить состояние объекта, вызвавшего исключение. |
| ® Простой |
Библиотека должна иметь прозрачную структуру, дающую возможность пользователю легко находить и подключать к приложению ее фрагменты. |
| ® Расширяемой |
Для пользователя должна быть реализована возможность включения в библиотеку новых классов. При этом архитектурная целостность среды разработки не должна нарушаться. |
Библиотека должна быть относительно небольших размеров; надо всегда помнить, что пользователь с большей охотой займется разработкой собственного кода, чем изучением чужого малопонятного класса.
Предполагается наличие трансляторов языка C++, поддерживающих параметризованные классы и обработку исключений. В целях обеспечения переносимости библиотеки она не должна зависеть от служб операционной системы.
Таким образом, первым результатом нашего анализа будет разделение всех абстракций на две категории:
| ® Структуры |
Содержит все структурные абстракции. |
| ® Инструменты |
Содержит все алгоритмические абстракции. |
Как мы скоро увидим, между этими двумя категориями существует отношение использования: некоторые инструменты построены на базе более примитивных свойств, обеспечиваемых структурами.
На втором этапе анализа мы постараемся выделить базовые классы, которые могут быть использованы в различных стандартных программах (чем шире будет круг рассмотренных приложений, тем лучше). Если в результате окажется, что некоторые из данных классов имеют много общего с абстракциями, определенными на первой стадии анализа, это будет знаком того, что ключевые абстракции были выявлены правильно. Можно составить длинный список специфических абстракций, присущих конкретным видам человеческой деятельности: валюта, астрономические координаты, единицы измерения массы и длины. Мы не будем включать подобные абстракции в нашу библиотеку, так как они либо слишком плохо поддаются формализации (валюта), либо очень специфичны (астрономические координаты), либо настолько примитивны, что нет смысла организовывать специально для них отдельные классы (единицы измерения массы и длины).
Проведя анализ, мы выделим следующие типы структур:
| ® Набор |
Множество различных элементов (в том числе дубликатов). |
| ® Множество |
Набор неповторяющихся элементов. |
| ® Коллекция |
Индексируемое множество элементов. |
| ® Список |
Последовательность элементов, имеющая начало; структурное разделение допускается. |
| ® Стек |
Последовательность элементов; элементы могут удаляться и добавляться только с одного конца. |
| ® Очередь |
Последовательность элементов, к которой можно добавлять элементы с одного конца, а удалять - с другого. |
| ® Дека |
Последовательность элементов, к которой можно добавлять и из которой можно удалять элементы с обоих концов. |
| ® Кольцо |
Последовательность элементов, к которой можно добавлять и из которой можно удалять элементы, находящиеся на вершине круговой структуры. |
| ® Строка |
Индексируемая последовательность элементов, в которой возможны операции с подстроками. |
| ® Ассоциативный массив |
Словарь пар "элемент/значение". |
| ® Дерево |
Набор (имеющий начало - корень дерева) вершин и ребер, которые не могут образовывать циклы и пересекаться; структурное разделение допускается. |
| ® Граф |
Множество вершин и ребер (без выделенного начального элемента), которое может содержать циклы и пересечения; структурное разделение допускается. |
Как уже говорилось в главе 4, упорядочение представленных выше абстракций есть проблема классификации. Мы выбрали именно такую модель из-за того, что она обеспечивает закрепление определенного поведения за каждой категорией объектов.
Обратите внимание на типы поведения, которые использовались в качестве критериев при разбиении на классы: некоторые структуры ведут себя как коллекции (наборы и множества), а другие - как последовательности (деки и стеки). В некоторых структурах (графы, списки и деревья) возможно структурное разделение, в то время как остальные более монолитны и не допускают структурного разделения своих элементов. Как мы увидим далее, подобная классификация поможет в дальнейшем сформировать достаточно простую архитектуру системы.
Для некоторых классов в процессе анализа выявилась желательность их функциональной изменчивости. В частности, нам могут понадобиться упорядоченные коллекции, деки и очереди (последние часто называют приоритетными очередями). Кроме того, мы можем различать ориентированные и неориентированные графы, односвязные и двусвязные списки, бинарные, множественные и AVL-деревья [AVL-дерево - предложенная Г.М.Адельсон-Вольским и Е.М.Ландисом конструкция подравниваемого бинарного дерева. - Примеч. ред.]. Эти специализированные абстракции могут быть получены уточнением одной из вышеперечисленных; их не следует выделять в отдельные большие категории.
Несмотря на то, что мы уже обнаружили признаки общности поведения, мы пока не будем заниматься проработкой иерархической структуры. На этапе анализа важно разобраться в ролях каждой абстракции.
Мы выделим следующие типы инструментов:
| ® Дата/Время |
Операции с датой и временем. |
| ® Фильтры |
Ввод, обработка и вывод. |
| ® Поиск по образцу |
Операции поиска последовательностей внутри других последовательностей. |
| ® Поиск |
Операции поиска элементов внутри структур. |
| ® Сортировка |
Операции упорядочивания структур. |
| ® Утилиты |
Составные операции, базирующиеся на базовых структурных операциях. |
Несомненно, существует масса различных функциональных вариантов этих абстракций. Можно, например, выделить несколько видов сортировок (быстрая сортировка методом пузырька, сортировка кучи и т.д.) или поиска (последовательный, двоичный, различные способы обхода дерева и т.д.). Как и раньше, мы отложим решения относительно наследования этих абстракций.
Модели взаимодействий
Итак, мы определили основные функциональные элементы нашей библиотеки; однако изолированные абстракции сами по себе - еще не среда разработки. Как отметил Вирфс-Брок: "Среда разработки предоставляет пользователю модель взаимодействий между объектами входящих в нее классов... Чтобы освоить среду разработки, прежде всего следует изучить методы взаимодействия и ответственности ее классов". Это и есть тот критерий, по которому можно отличить среду разработки от простого набора классов: среда - это совокупность классов и механизмов взаимодействия экземпляров этих классов.
Анализ показывает, что существует определенный набор основных механизмов, необходимый для библиотеки базовых классов:
-
семантика времени и памяти;
-
управление хранением данных;
-
обработка исключений;
-
идиомы итерации;
-
синхронизация при многопоточности.
При проектировании системы базовых классов необходимо сохранять баланс между перечисленными техническими требованиями [Действительно, как отмечает Страуструп, "разработка универсальной библиотеки значительно сложнее, чем разработка отдельной программы" [10]]. Если мы будем пытаться решить каждую задачу по отдельности, то, скорее всего, получим ряд изолированных решений, не связанных между собой ни общими протоколами, ни общей концепцией, ни реализацией. Такой наивный подход приведет к изобилию различных подходов, которое испугает потенциального пользователя получившейся библиотеки.
Встанем на точку зрения пользователя нашей библиотеки. Какие абстракции представляют имеющиеся в ней классы? Как они взаимодействуют между собой? Как их можно приспособить к предметной области? Какие классы играют ключевую роль, а какие можно вообще не использовать? Вот те вопросы, на которые нужно дать ответ перед тем, как предлагать пользователям библиотеку для решения нетривиальных задач. К счастью для пользователя, ему не обязательно во всех деталях представлять себе, как работает библиотека, подобно тому, как не нужно понимать принципы работы микропроцессора для программирования на языке высокого уровня. В обоих случаях реализации нижнего уровня может быть продемонстрирована каждому пользователю, но только при его желании.
Рассмотрим описание абстракций нашей библиотеки с двух точек зрения: пользователя, который только объявляет объекты уже существующих классов, и клиента, который конструирует собственные подклассы на базе библиотечных. При проектировании с расчетом на первого пользователя желательно как можно сильнее ограничить доступ к реализациям абстракций и сконцентрироваться на их ответственностях; проектирование с учетом запросов второго пользователя предполагает открытость некоторых внутренних деталей реализации, однако, не настолько, чтобы стало возможным нарушить фундаментальную семантику абстракции. Таким образом, приходится отметить некоторую противоречивость основных требований к системе.
Одной из главных проблем при работе с большой библиотекой являются трудности в понимании того, какие, собственно, механизмы она включает в себя. Перечисленные выше модели представляют собой как бы душу архитектуры библиотеки: чем больше разработчик знает об этих механизмах, тем легче ему будет использовать существующие в библиотеке компоненты, а не сочинять с нуля собственные. На практике получается так, что пользователь сначала знакомится с содержанием и работой наиболее простых классов, и только затем, проверив надежность их работы, постепенно начинает использовать все более сложные классы. В процессе разработки, по мере того как начинают вырисовываться новые, присущие предметной области пользователя, абстракции, они тоже могут добавляться в библиотеку. Развитие объектно-ориентированной библиотеки - это длительный процесс, проходящий через ряд промежуточных этапов.
Именно так мы будем строить нашу библиотеку: сначала определим тот архитектурный минимум, который реализует все пять выделенных нами механизмов, и затем начнем постепенно наращивать на этом остове все новые и новые функции.
9.2. Проектирование
Тактические вопросы
В соответствии с законом разработки программ Коггинса "прагматизм всегда должен быть предпочтительней элегантности, ведь Природу все равно ничем не удивить". Следствие: проектирование никогда не будет полностью независимым от языка реализации проекта. Особенности языка неизбежно наложат отпечаток на те или иные архитектурные решения, и их игнорирование может привести к тому, что нам придется работать в дальнейшем с абстракциями, не в полной мере учитывающими преимущества и недостатки конкретного языка реализации.
Как было отмечено в главе 3, объектно-ориентированные языки предоставляют три основных механизма упорядочения большего числа классов: наследование, агрегацию и параметризацию. Наследование является наиболее популярным свойством объектно-ориентированной технологии, однако далеко не единственным принципом структурирования. Как мы увидим, сочетание параметризации с наследованием и агрегацией помогает создать достаточно мощную и в то же время компактную архитектуру.
Рассмотрим усеченное описание предметно-зависимого класса очереди в
C++:
class NetworkEvent... // сетевое событие
class EventQueue { // очередь событий
public:
EventQueue();
virtual ~EventQueue();
virtual void clear(); // очистить
virtual void add(const NetworkEvent&); // добавить
virtual void pop(); // продвинуть
virtual const NetworkEvent& front() const; // первый элемент
...
};
Перед нами абстракция, олицетворяющая очередь событий: структура, в которую мы можем добавлять новые элементы в конец очереди и удалять элементы из начала очереди. C++ позволяет скрыть внутренние детали реализации класса очереди за его внешним интерфейсом (операциями clear, add, pop и front ).
Нам могут потребоваться также некоторые другие варианты очереди, например, приоритетная очередь, где события выстраиваются в соответствии с их срочностью. Разумно воспользоваться результатами уже проделанной работы и организовать новый класс на базе ранее определенного:
class PriorityEventQueue : public EventQueue {
public:
PriorityEventQueue();
virtual ~PriorityEventQueue();
virtual void add(const NetworkEvent&);
...
};
Виртуальность функций (например функции add) поощряет переопределение операций в подклассах.
Комбинация наследования с параметризованными классами позволяет создавать еще более общие абстракции. Семантика класса очереди не зависит от того, что в ней: волки или овцы. Используя классы-шаблоны, можно переопределить наш базовый класс следующим образом:
template<class Item>
class Queue {
public:
Queue();
virtual ~Queue();
virtual void clear();
virtual void add(const Item&);
virtual void pop();
virtual const Item& front() const;
...
};
Это наиболее распространенный способ использования параметризованных классов: взять существующий конкретный класс, выделить в нем то, что не зависит от элементов, с которыми он оперирует, и сделать эти элементы аргументами шаблона.
Наследование и параметризация очень хорошо сочетаются. Наш подкласс PriorityQueue можно, например, обобщить следующим образом:
template<class Item>
class PriorityQueue : public Queue<Item> {
public:
PriorityQueue();
virtual ~PriorityQueue();
virtual void add(const Item&);
...
};
Безопасность с точки зрения типов - ключевое преимущество данного подхода. Мы можем создать целый ряд различных классов конкретных очередей:
Queue<char> characterQueue;
typedef Queue<MetworkEvent> EventQueue;
typedef PriorityQueue<NetworkEvent> PriorityEventQueue;
 Рис. 9-1. Наследование и параметризация.
Рис. 9-1. Наследование и параметризация.
При этом язык реализации не позволит нам присоединить событие к очереди символов, а вещественное число - к очереди событий.
Рис. 9-1 иллюстрирует отношения между параметризованным классом (Queue), его подклассом (PriorityQueue), примером этого подкласса (PriorityEventQueue) и одним из его экземпляров (mailQueue).
Этот пример подтверждает правильность одного из самых первых наших архитектурных решений: почти все классы нашей библиотеки должны быть параметризованными. Тогда будет выполнено и требование защищенности.
Макроорганизация
Как уже отмечалось в предыдущих главах, классы есть необходимое, но не достаточное средство декомпозиции системы. Это замечание в полной мере касается и библиотеки классов. Неупорядоченный набор классов, в котором разработчики копаются в поисках чего-либо полезного, - едва ли не худшее из возможных решений. Лучше разбить классы на отдельные категории (рис. 9-2). Такое решение позволяет удовлетворить требованию простоты библиотеки.
При первом взгляде на проблемную область легко заметить, что мы могли бы воспользоваться общими функциональными свойствами классов. Поэтому заведем общедоступную категорию Support (поддержка) для абстракций низкого уровня и классов, поддерживающих общие механизмы библиотеки.
Это наблюдение приводит нас ко второму принципу архитектуры библиотеки: четкое разделение между политикой и реализацией. Такие абстракции, как очереди, множества и кольца, отражают политику использования низкоуровневых структур: связных списков или массивов. Очередь, например, выражает политику, при которой можно только удалять элементы из начала структуры и добавлять элементы к ее концу. Множество, с другой стороны, не представляет никакой политики, требующей упорядочения элементов. Кольцо требует упорядочения, но предполагает, что начальный и конечный элемент соединены. К категории Support мы будем относить простые абстракции - те, над которыми надстраивается политика.
Поместив эту категорию классов в код библиотеки, мы поддерживаем библиотечное требование расширяемости. Основная масса разработчиков, может быть, и не будет использовать классы из Support. Однако разработчики библиотек и более продвинутые программисты смогут задействовать базовые абстракции из Support для конструирования новых классов или модификации поведения существующих.
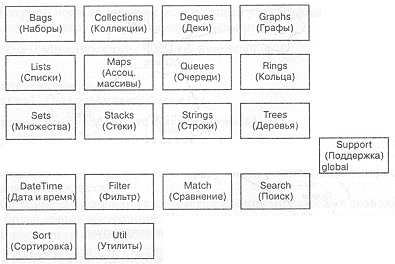 Рис. 9-2. Категории классов в библиотеке.
Рис. 9-2. Категории классов в библиотеке.
Как видно из рис. 9-2, библиотека организована не в виде дерева, а в виде леса классов; здесь не существует единого базового класса, как этого требуют языки типа Smalltalk.
На рисунке этого не видно, но на самом деле классы категорий Graphs, Lists и Trees несколько отличаются от других структурных классов. Еще раньше мы отмечали, что абстракции типа деки и стека являются монолитными. С монолитной структурой можно иметь дело только как с единым целым: ее нельзя разбить на отдельные идентифицируемые компоненты, и таким образом гарантируется ссылочная целостность. С другой стороны, в композитной структуре (такой как граф) структурное разделение допускается. В ней мы можем, например, получать доступ к подспискам, ветвям дерева, отдельным вершинам или ребрам графа. Фундаментальное различие между этими двумя категориями структур лежит в семантике операций копирования, присваивания и сравнения. Для монолитных абстракций подобные операции можно назвать "глубокими", а для композитных абстракций - "поверхностными", в том смысле, что при копировании происходит передача ссылки на часть общей структуры.
Семейства классов
Третий основной принцип проектирования библиотеки заключается в построении семейств классов, связанных отношением наследования. Для каждого типа структур мы создадим несколько различных классов, объединенных единым интерфейсом (как в случае с абстрактным классом Queue), но с разными конкретными подклассами, имеющими несколько различные представления и поэтому отличающимися Своим устройством и характеристиками "время/память". Таким образом мы обеспечим библиотечное требование полноты. Разработчик сможет выбрать тот конкретный класс, который в большей степени подходит для решения его задачи. В то же время этот класс обладает тем же интерфейсом, что и остальные классы семейства. Сознательное четкое разделение абстрактного базового класса и его конкретных подклассов позволяет пользователю системы выбрать, скажем, на первом этапе проектирования один из классов в качестве рабочего, а затем, в процессе доводки приложения, заменить его на другой, чем-то отличающийся класс того же семейства, затратив на это минимум времени и усилий (единственное, что ему потребуется, - это заново оттранслировать свою программу). При этом разработчик будет уверен в нормальном функционировании программы, так как все классы, принадлежащие одному семейству, обладают идентичным внешним интерфейсом и схожим поведением. Смысл в такой организации классов состоит еще и в возможности копирования, присваивания и сравнения объектов одного семейства даже в том случае, если их представления совершенно разнятся.
Можно сказать, что базовый абстрактный класс как бы содержит в себе все важные черты абстракции. Другое важное применение абстрактных базовых классов - это кэширование общего состояния, которое дорого вычислять заново. Так можно перевести вычисление O(n) в операцию порядка O(1) - простое считывание данных. При этом, естественно, требуется обеспечить соответствующий механизм взаимодействия между абстрактным базовым классом и его подклассами, чтобы гарантировать актуальность кэшируемого значения.
Элементы семейства классов представляют собой различные формы абстракции. Опыт показывает, что существуют две основные формы абстракций, которыми следует пользоваться разработчику при создании серьезных приложений. Во-первых, это форма конкретного представления абстракции в оперативной памяти машины. Существует два варианта такого представления: выделение памяти для структуры из стека или выделение оперативной памяти из кучи. Им соответствуют две формы абстракций: ограниченная и неограниченная:
| ® Ограниченная |
Структура хранится в стеке и, таким образом, имеет статический размер (известный в момент создания объекта). |
| ® Неограниченная |
Структура хранится в куче и ее размеры могут динамически изменяться. |
Так как ограниченная и неограниченная формы абстракции имеют общие интерфейс и поведение, их обе можно представить в виде прямых подклассов абстрактного базового класса для каждой структуры. Мы обсудим эти и другие особенности организации данных в следующих разделах.
Второй вариант связан с синхронизацией. Как было отмечено в главе 2, множество полезных приложений обходятся одним процессом. Их называют последовательными системами, потому что они используют один поток управления. Для других приложений (особенно это касается систем реального времени) требуется обеспечить синхронизацию нескольких одновременно выполняемых потоков. Такие системы называются параллельными, и в них каким-то образом должно обеспечиваться взаимное исключение процессов, конкурирующих за один и тот же ресурс. Ясно, что нельзя дать возможность управлять одним и тем же объектом одновременно нескольким потокам, это в конце концов приведет к нарушению его состояния. Рассмотрим, например, поведение двух агентов, которые одновременно пытаются добавить элемент одному и тому же объекту класса Queue. Первый агент, начавший добавление элемента, может быть прерван раньше, чем окончит данную операцию, и оставит объект второму агенту в незавершенном состоянии.
 Рис. 9-3. Семейства классов.
Рис. 9-3. Семейства классов.
Как отмечалось в главе 3, в данном случае при проектировании существуют всего три возможных альтернативы, каждая из которых требует обеспечения различного уровня взаимодействия между агентами, оперирующими с общими объектами:
-
последовательный;
-
защищенный;
-
синхронизированный.
Мы рассмотрим каждый из этих вариантов более подробно в следующем разделе. Обеспечение взаимодействия между абстрактным базовым классом, формами его представления и формами синхронизации порождает для каждой структуры семейство классов, подобное тому, которое приведено на рис. 9-3. Теперь можно понять, почему мы в свое время решили организовать библиотеку именно в виде семейств классов, а не в виде единого дерева. Это было сделано из-за того, что такая архитектура:
-
Отражает общность различных форм.
-
Позволяет осуществлять более простой доступ к элементам библиотеки.
-
Позволяет избежать бесконечных метафизических споров о "чистом объектно-ориентированном подходе".
-
Упрощает интеграцию системы с другими библиотеками.
Микроорганизация
В целях обеспечения простоты работы с системой выберем один общий стиль оформления структур и механизмов библиотеки:
template<...>
class Name : public Superclass {
public:
// конструкторы
// виртуальный деструктор
// операторы
// модификаторы
// селекторы
protected:
// данные
// функции
private:
// друзья
};
Описание абстрактного базового класса Queue начинается следующим образом:
template<class Item> class Queue {
Сигнатура шаблона template служит для задания аргументов параметризованного класса. Отметим, что в C++ шаблоны сознательно введены таким образом, чтобы передать достаточную гибкость (и ответственность) в руки разработчика, инстанцирующего шаблон в своем приложении.
Далее определим обычный список конструкторов и деструкторов:
Queue();
Queue(const Queue<Item>&);
virtual ~Queue();
Отметим, что мы описали деструктор виртуальным, чтобы обеспечить полиморфное поведение при уничтожении объектов класса. Далее объявим все операторы:
virtual Queue<Item>& operator=(const Queue<Item>&);
virtual int operator==(const Queue<Item>&) const;
int operator!=(const Queue<Item>&) const;
Мы определили оператор присваивания (operator==) и оператор сравнения (operator==) как виртуальные для того, чтобы обеспечить безопасность типов. Переопределение этих операторов входит в обязанности подклассов. В них будут использоваться функции, аргументом которых является объект собственного специализированного класса. В этом смысле подклассы имеют то преимущество, что они знают представление своих экземпляров и могут обеспечить очень эффективную реализацию. Когда конкретный подкласс очереди неизвестен (например, если мы передаем объект по ссылке на его базовый класс), вызывается оператор базового класса, использующий может быть менее эффективные, но более универсальные алгоритмы. Эта идиома имеет побочный эффект: возможность работы одной и той же функции с очередями, имеющими различную внутреннюю реализацию, без нарушения типизации.
Если мы хотим ограничить доступ к копированию, присваиванию или сравнению некоторых объектов, нам надо объявить эти операторы защищенными или закрытыми.
Определим теперь модификаторы, позволяющие менять состояние объекта:
virtual void clear() = 0;
virtual void append(const Item&) = 0;
virtual void pop() =0;
virtual void remove (unsigned int at) = 0;
Данные операции объявлены как чисто виртуальные, а это значит, что их описание является обязанностью подклассов. Наличие чисто виртуальных функций делает класс Queue абстрактным.
Спецификатор const указывает (компилятор может это проверить) на использование функций-селекторов, то есть функций, предназначенных исключительно для получения информации о состоянии объекта, но не для изменения состояния:
virtual unsigned int length() const = 0;
virtual int isEmpty() const = 0;
virtual const Item& front() const =0;
virtual int location(const Item&) const = 0;
Эти операции тоже определены как чисто виртуальные, потому что класс Queue не обладает достаточной информацией для их полного описания.
Защищенная часть каждого класса начинается с описания тех элементов, которые формируют основу его структуры и должны быть доступны подклассам [Всюду, где веские причины не заставляют нас действовать по-другому, мы объявляем элементы класса закрытыми. Здесь, однако, существует веская причина объявить эти фрагменты защищенными: доступ к ним потребуется подклассам]. Абстрактный класс Queue, в. отличие от своих подклассов (см. ниже), подобных элементов не имеет.
Продолжит защищенную часть базового класса определение служебных функций, которые будут полиморфно реализованы в конкретных подклассах. Класс Queue содержит довольно типичный список таких функций:
virtual void purge() = 0;
virtual void add(const Item&) = 0;
virtual unsigned int cardinality() const = 0;
virtual const Item& itemAt (unsigned int) const = 0;
virtual void lock();
virtual void unlock();
Причины, по которым мы ввели именно эти функции, будут рассмотрены в следующем разделе.
И, наконец, определим закрытую часть, обычно содержащую объявления о классах-друзьях и те элементы, которые мы хотим сделать недоступными даже для подклассов. Класс Queue содержит только декларации о друзьях:
friend class QueueActiveIterator<Item>;
friend class QueuePassiveIterator<Item>;
Как мы увидим в дальнейшем, эти объявления друзей понадобятся для поддержки идиом итератора.
Семантика времени и памяти
Из пяти основных принципов строения библиотеки базовых классов, возможно, наиболее важен механизм, обеспечивающий клиента альтернативной простанственно-временной семантикой внутри каждого семейства классов.
Рассмотрим тот спектр требований, который должен учитываться при разработке библиотеки общего назначения. На рабочей станции, обладающей большим виртуальным адресным пространством, пользователь скорее всего будет расточать память ради более высокого быстродействия. С другой стороны, в некоторых встроенных системах, таких, как спутник или автомобильный мотор, ресурсы памяти часто ограничены, и разработчик вынужден выбирать в качестве рабочих те абстракции, которые используют меньше памяти (например, выделяя место под данные в стеке, а не в "куче"). Ранее мы различили эти две возможности как ограниченную и неограниченную формы соответственно.
Неограниченные формы применимы в тех случаях, когда размер структуры не может быть предсказан, а выделение и утилизация памяти из кучи не приводит ни к потере времени, ни к снижению надежности (как это бывает в некоторых приложениях, критичных по времени) [Некоторые требования к системе могут запретить использование динамически распределяемой памяти. Рассмотрим сердечный импульсный регулятор и возможные фатальные результаты, которые может вызвать сборщик мусора, "проснувшийся" в неподходящий момент. Есть системы с длительным рабочим циклом: в них даже минимальная утечка памяти может дать серьезный кумулятивный эффект; вынужденная перезагрузка системы из-за недостатка памяти может привести к неприемлемой потере функциональности]. Ограниченные формы лучше подходят для работы с небольшими структурами, размер которых достаточно хорошо предсказуем. Учтем также, что динамическое выделение памяти менее терпимо к ошибкам программиста.
Таким образом, все структуры данной библиотеки должны присутствовать в альтернативных вариантах; поэтому нам придется создать два низкоуровневых класса поддержки, Unbounded (неограниченный) и Bounded (ограниченный). Задачей класса unbounded является поддержка быстро работающего связного списка, элементы которого размещаются в памяти, выделенной из "кучи". Это представление эффективно по скорости, но не по памяти, так как каждый элемент списка должен, кроме своего значения, дополнительно содержать указатель на следующий элемент того же списка. Задача класса Bounded состоит в организации структур на базе массива, что эффективно с точки зрения памяти, но добиться большой производительности трудно, так как, например, при добавлении элемента в середину списка приходится последовательно копировать все последующие (или предыдущие) элементы массива.
Как видно из рис. 9-4, для включения этих классов нижнего уровня в иерархию основных абстракций мы используем агрегацию. Более точно, диаграмма показывает, что мы используем физическое включение по значению с защищенным Доступом, которое означает, что это низкоуровневое представление доступно только подклассам и друзьям. На раннем этапе проектирования мы хотели воспользоваться примесями и сделать unbounded и Bounded защищенными суперклассами.
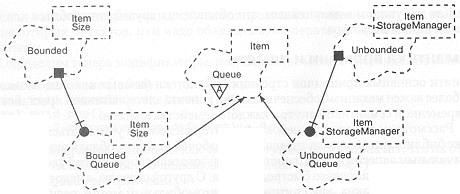 Рис. 9-4. Ограниченная и неограниченная формы.
Рис. 9-4. Ограниченная и неограниченная формы.
Мы в конце концов отказались от такого варианта, так как он достаточно труден для понимания, и к тому же нарушает лакмусов принцип наследования: BoundedQueue, по крайней мере, с точки зрения типа данных, не является частным случаем класса Bounded.
Отметим также, что работа с двумя формами требует присутствия второго аргумента в их шаблоне. Для ограниченной формы - это беззнаковое целое число Size, обозначающее статический размер объекта. Для неограниченной формы - это класс StorageManager, ответственный за политику размещения в памяти. Мы рассмотрим его работу в следующем разделе.
Протокол обоих классов поддержки должен быть, с одной стороны, достаточным для обеспечения работы конкретных подклассов, а с другой стороны, универсальным, чтобы гарантировать выполнение ответственности всех других структур в библиотеке. В целях компактности и быстродействия мы не включили в описание классов Unbounded и Bounded ни одной виртуальной функции. По этой причине мы не можем объединить их одним суперклассом, несмотря на то, что они имеют общий протокол; кроме того, мы не можем надлежащим образом построить на их базе иерархию подклассов. В данном случае гибкость приносится в жертву производительности. По той же причине мы решаем сделать ряд функций встроенными; хорошими кандидатами на это обычно являются селекторы, особенно те, которые возвращают простые переменные.
Рассмотрим, например, описание класса Bounded:
template<class Item, unsigned int Size>
class Bounded {
public:
Bounded();
Bounded(const Bounded<Item, Size>&);
~Bounded();
Bounded<Item, Size>& operator=(const Bounded<Item,
Size>&);
int operator==(const Bounded<Item, Size>&) const;
int operator!=(const Bounded<Item, Size>&) const;
const Item& operator[](unsigned int index) const;
Item& operator[](unsigned int index);
void clear();
void insert(const Item&);
void insert(const Item&, unsigned int before);
void append(const Item&);
void append(const Item&, unsigned int after);
void remove(unsigned int at);
void replace(unsigned int at, const Item&);
unsigned int available() const;
unsigned int length() const;
const Item& first() const;
const Item& last() const;
const Item& itemAt(unsigned int) const;
Item& itemAt(unsigned int);
int location(const Item&) const;
static void* operator new(size_t);
static void operator delete(void*, size_t);
protected:
Item rep[Size];
unsigned int start;
unsigned int stop;
unsigned int expandLeft(unsigned int from);
unsigned int expandRight(unsigned int from);
void shrinkLeft(unsigned int from);
void shrinkRight(unsigned int from);
};
Объявление класса следует схеме, описанной ранее. Каким образом мы пришли именно к такому решению? Если честно, то на 80% это результат чистого проектирования классов, которое рассматривалось в главе 6. Затем интерфейс дорабатывался в соответствии с результатами пробного использования класса совместно с рядом основных абстракций системы. Основная трудность при эволюции состояла в идентификации подходящих примитивных операций, которые должны использоваться при работе с набором различных структур.
Сердцем класса является защищенный массив rep постоянного размера Size. Рассмотрим следующее объявление:
Bounded<char, 100U> charSequence;
При создании соответствующего объекта в стеке образуется массив постоянного размера из 100 элементов. Защищенные члены класса start и stop (индексы в этом массиве) указывают начало и конец последовательности. Тем самым мы использовали кольцевой буфер данных. Добавление нового элемента в начало или в конец последовательности не потребует перемещения данных, а добавление элемента в середину массива приводит к копированию не более чем половины его элементов.
Проектирование ограниченного и неограниченного классов поддержки затрагивает также некоторые тонкие вопросы, касающиеся использования ссылок (мы упоминали о них в главе 3). Нам придется еще раз коснуться этой темы, и не только потому, что она имеет прямое отношение к разработке интерфейса параметризованных классов, но и потому, что данные вопросы сами по себе представляют значительный интерес для проектировщика любой более или менее нетривиальной библиотеки.
В C++ ссылки являются механизмом, позволяющим улучшить производительность. Однако пользоваться ими следует предельно осторожно во избежание нарушения корректного доступа к оперативной памяти. В данной библиотеке мы используем ссылки для ускорения работы при передаче аргументов функциям-членам. Это касается, например, класса Bounded, где подобным образом передаются ссылки на объекты классов Bounded и Item. Ссылки, как правило, не используются для передачи примитивных объектов (например, целых чисел в описании функции-члена itemAt) - программа от этого будет работать только медленнее. Кроме того, семантика языка C++ порождает некоторые опасности при манипулировании с временными объектами.
Все наши структуры, однако, содержат в качестве элементов не ссылки, а значения, что исключает возникновение ссылок на временные объекты в стеке при работе программы. По той же причине мы отказались от хранения указателей на элементы структур, так как это вызывает крайне нестабильное поведение системы при инстанцировании шаблона встроенными типами данных. Подобные вопросы чрезвычайно существенны при проектировании сред разработки, включающих в себя параметризованные классы, так как пользователь может инстанцировать шаблон произвольным типом данных. При использовании ссылок существуют, вообще говоря, три случая, и нам придется при создании библиотеки постараться найти определенный баланс между ними.
Во-первых, встроенные типы данных можно без труда передавать по ссылке и копировать. Объявив типы аргумента постоянными ссылками, можно избежать неприятностей, связанных с появлением временных структур, возникающих при приведении типов [12].
Во-вторых, типы данных, определенные пользователем, также можно передавать по ссылке и копировать, но только в том случае, когда для них определены копирующий конструктор и оператор присваивания. Ссылки можно использовать в полиморфных операциях (передавая объект производного класса вместо объявленного при инстанцировании), но копирование не будет полиморфным. В результате объект будет "срезан" до размеров своего базового класса.
В-третьих, при полиморфном использовании библиотеки встретится инстанцирование шаблонов указателями на базовый класс. Хотя передача указателей по ссылке может и не улучшить производительность, но копирование указателей в представление сохраняет полиморфизм производных объектов.
Например, для класса BoundedQueue мы можем написать следующее:
class Event ... typedef Event* EventPtr;
BoundedQueue<int, 10U> intQueue;
BoundedQueue<Event, 50U> eventQueue1;
BoundedQueue<EventPtr, 100U> eventQueue2;
С помощью объекта класса eventQueue1 можно спокойно создавать очереди событий, однако при добавлении в очередь экземпляра любого подкласса Event произойдет "срезка", и полиморфное поведение такого экземпляра будет потеряно. С другой стороны, объект класса eventQueue2 содержит указатели на объекты класса Event, поэтому проблема "срезки" не возникает.
Наше решение, касающееся хранения внутри структур значений, а не ссылок, предъявляет определенные требования к конструкторам и деструкторам элементов. В частности, классы, используемые для инстанцирования структуры, должны, по крайней мере, иметь конструктор по умолчанию, копирующий конструктор и оператор присваивания. Кроме того, в некоторых случаях элементы не могут быть уничтожены сразу после удаления из структуры. В ограниченной форме, например, элементы (хранящиеся в массивах) не уничтожаются до уничтожения всей структуры.
Посмотрим, как можно использовать класс Bounded при формировании конкретного класса BoundedQueue. Отметим, что абстракция BoundedQueue содержит защищенный элемент rep класса Bounded.
template<class Item, unsigned int Size>
class BoundedQueue : public Queue<Item> {
public:
BoundedQueue();
BoundedQueue(const BoundedQueue<Item, Size>&);
virtual ~BoundedQueue();
virtual Queue<Item>& operator=(const Queue<Item>&);
virtual Queue<Item>& operator=(const BoundedQueue<Item,
Size>&);
virtual int operator==(const Queue<Item>&) const;
virtual int operator=(const BoundedQueue<Item, Size>&)
const;
int operator!=(const BoundedQueue< Item, Size>&) const;
virtual void clear();
virtual void append(const Item&);
virtual void pop();
virtual void remove(unsigned int at);
virtual unsigned int available() const;
virtual unsigned int length() const;
virtual int isEmpty() const;
virtual const Item& front() const;
virtual int location(const Item&) const;
protected:
Bounded<Item, Size> rep;
virtual void purge();
virtual void add(const Item&);
virtual unsigned int cardinality() const;
virtual const Item& itemAt(unsigned int) const;
static void* operator new(size_t);
static void operator delete(void*, size_t);
};
Основная задача данного класса - завершить протокол, определенный в
базовом классе. Часто это означает немного больше, чем простая передача
обязанности классу более низкого уровня Bounded, как предлагается
в следующей реализации:
template<class Item, unsigned int Size>
unsigned int BoundedQueue<Item, Size>::length() const
{
return rep.length();
}
Отметим, что в описание класса BoundedQueue включены некоторые дополнительные операции, которых нет в его суперклассе. Добавлен селектор available, возвращающий количество свободных элементов в структуре (вычисляется как разность Size - length()). Эта операция не включена в описание базового класса главным образом из-за того, что для неограниченной модели вычисление свободного места не очень осмысленно. Мы также переопределили оператор присваивания и проверку равенства. Как уже отмечалось ранее, это позволяет применить более эффективные алгоритмы по сравнению с базовым классом, так как подклассы лучше знают, что и как делать. Добавленные операторы new и delete определены в защищенной части класса, чтобы лишить клиентов возможности произвольно динамически размещать экземпляры BoundedQueue (что согласуется со статической семантикой этой конкретной формы).
Класс Unbounded имеет, в существенном, тот же протокол, что и класс Bounded, однако его реализация совершенно другая.
template<class Item, class StorageManager>
class Unbounded {
public:
...
protected:
Node<Item, StorageManager>* rep;
Node<Item, StorageManager>* last;
unsigned int size;
Node<Item, StorageManager>* cache;
unsigned int cacheIndex;
};
Форма Unbounded реализует очередь как связный список узлов, где узел (Node) реализован следующим образом:
template<class Item, class StorageManager>
class Node {
public:
Node(const Item& i,
Node<Item, StorageManager>* previous, Node<Item, StorageManager>*
next);
Item item;
Node<Item, StorageManager>* previous;
Node<Item, StorageManager>* next;
static void* operator new(size_t);
static void operator delete(void*, size_t);
};
Основная задача этого класса - управлять одним элементом списка и указателями на предыдущий и следующий узлы. Данная абстракция отнесена к категории классов поддержки, к ней не имеют доступ внешние пользователи, и поэтому мы решили несколько ослабить наши традиционные строгие требования к инкапсуляции, сделав все элементы класса открытыми и жертвуя таким образом безопасностью ради эффективности.
Помня, что классы Bounded и Unbounded имеют практически идентичный внешний протокол, а, значит, их функциональные свойства во многом подобны, можно предположить, что и реализация будет схожей. Однако различие во внутреннем представлении классов приводит к существенно различной пространственно-временной семантике. Манипуляции с узлами связанного списка, например, осуществляются очень быстро, однако процедура нахождения нужного элемента будет занимать время порядка O(n). Поэтому наше представление кэширует последний узел, к которому было обращение, в надежде, что следующее обращение будет либо к этому же узлу, либо к его соседям. Схема же, базирующаяся на массивах, дает низкое быстродействие (в худшем случае порядка O(n/2) если элемент расположен в середине массива) при добавлении или удалении элементов, однако обеспечивает высокую скорость поиска (порядка O(1)).
Управление памятью
Задача управления памятью возникает для неограниченных форм реализации. В этом случае разработчик библиотеки должен определить политику выделения и освобождения памяти из кучи при осуществлении операций над узлами. Наивный подход просто использует глобальные функции new и delete, что не может обеспечить достаточной производительности системы. Кроме того, на некоторых компьютерных платформах управление памятью крайне усложнено (например, при наличии сегментированного адресного пространства в некоторых операционных системах персональных компьютеров) и требует разработки специальной стратегии, жестко привязанной к определенной операционной среде. Для нашей библиотеки надо четко выделить подсистему управления памятью.
На рис. 9-5 приведен выбранный для данной библиотеки механизм управления памятью [Историческое замечание: потребовалось около четырех итераций архитектуры библиотеки, чтобы придти именно к этому механизму, который - что не удивительно - оказался самым простым. Предыдущие варианты, от которых мы в конце концов отказались, были недостаточно гибкими, трудными для объяснения и стремились навязать особенности реализации безразличным к ней клиентам]. Рассмотрим сценарий, иллюстрацией которого служит данная диаграмма:
-
Клиент (aClient) вызывает операцию добавления (append) для экземпляра класса UnboundedQueue (более точно, экземпляра класса, инстанцированного из UnboundedQueue).
-
UnboundedQueue, в свою очередь, передает выполнение операции своему элементу rep, который является экземпляром класса unbounded.
-
Unbounded, вызывая свою статическую функцию new, выделяет необходимый объем адресного пространства для размещения нового экземпляра
Node.
-
Этот экземпляр Node, в свою очередь, делегирует ответственность за выделение памяти своему StorageManager, который доступен классу, инстанцируемому из UnboundedQueue (и, следовательно, классам Unbounded и Node), как аргумент шаблона. StorageManager разделяется всеми экземплярами и служит для обеспечения последовательной политики выделения памяти на уровне класса.
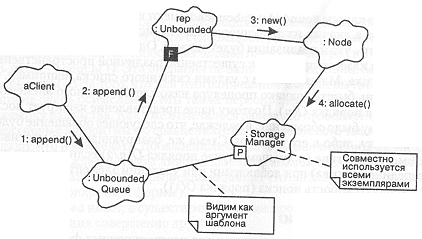 Рис. 9-5. Механизм управления памятью.
Рис. 9-5. Механизм управления памятью.
Передавая StorageManager в качестве аргумента всем неограниченным структурам, мы четко отделяем политику организации доступа к памяти от ее реализации и даем пользователям возможность добавлять в программу свои собственные концепции управления памятью, не меняя при этом содержания библиотеки. Это классический пример того, как можно добиться открытости программной системы через инстанцирование, не прибегая к наследованию.
Единственное требование, предъявляемое к вариантам StorageManager, заключается в необходимости сохранения единого протокола. В частности, все они должны содержать открытые функции-члены allocate и deallocate, предназначенные соответственно для выделения и освобождения памяти. Рассмотрим в качестве примера простейший вариант такого класса:
class Unmanaged {
public:
static void* allocate(size_t s) {return ::operator new(s);}
static void deallocate(void* p, size_t) {::operator delete(p);}
private:
Unmanaged() {}
Unmanaged(Unmanaged&) {}
void operator=(Unmanaged&) {}
void operator==(Unmanaged&) {}
void operator!=(Unmanaged&) {}
};
Обратите внимание на идиому, которая применяется, чтобы пользователь не мог копировать, присваивать и сравнивать экземпляры данного класса.
Протокол класса Unmanaged реализован через встроенные вызовы глобальных операторов new и delete. Мы назвали данную абстракцию Unmanaged, не требующей управления, так как она фактически не представляет собой ничего нового, а просто повторяет уже существующий системный механизм. Требующей управления названа другая абстракция, реализующая гораздо более эффективный алгоритм. В соответствии с этим алгоритмом память под узлы выделяется из некоего общего пула памяти. Если узел не используется, он помечается как свободный. Если возникает необходимость в новом узле, используется один из списка свободных. Выделение новой памяти из кучи происходит только в случае, если этот список пуст. Таким образом, часто удается избежать обращения к сервисным функциям операционной системы: выделение памяти сводится лишь к манипулированию указателями, что гораздо быстрее [В языке C++ глобальный оператор new так или иначе вызывает какой-либо вариант функции malloc - операции довольно дорогой].
При желании можно еще улучшить наш механизм, например, введя новую операцию для выделения памяти заранее, до того, как она понадобится. И наоборот, в определенных ситуациях, когда неиспользованных участков становится слишком много, можно дефрагментировать пул, и вернуть освободившуюся память в кучу. Можно предусмотреть операцию, позволяющую пользователю определить размер кластера памяти, и, таким образом, настроить класс под конкретное приложение.
В соответствии с приведенными выше соображениями, соответствующий класс поддержки можно определить следующим образом:
class Pool {
public:
Pool(size_t chunkSize);
~Pool();
void* allocate(size_t);
void deallocate(void*, size_t);
void preallocate(unsigned int numberOfChunks);
void reclaimUnusedChunks();
void purgeUnusedChunks();
size_t chunkSize() const;
unsigned int totalChunks() const;
unsigned int numberOfDirtyChunks() const;
unsigned int numberOfUnusedChunks() const;
protected:
struct Element ...
struct Chunk ...
Chunk* head;
Chunk* unusedChunks;
size_t repChunkSize;
size_t usableChunkSize;
Chunk* getChunk(size_t s);
};
Описание содержит два вложенных класса Element и chunk (отрезок). Каждый экземпляр класса Pool управляет связным списком объектов chunk, представляющих собой отрезки "сырой" памяти, но трактуемых как связные списки экземпляров класса Element (это один из важных аспектов, управляемых классом pool). Каждый отрезок может отводиться элементам разного размера и для эффективности мы сортируем список отрезков в порядке возрастания их размеров. Менеджер памяти может быть определен следующим образом:
class Managed {
public:
static Pool& pool;
static void* allocate(size_t s) {return pool.allocate(s);
}
static void deallocate(void* p, size_t s) {pool.deallocate(p,
s);}
private:
Managed() {}
Managed(Managed&) {}
void operator=(Managed&) {}
void operator==(Managed&) {}
void operator!=(Managed&) {}
};
Этот класс имеет тот же внешний протокол, что и Unmanaged. Из-за того, что в C++ шаблоны сознательно недостаточно четко определены, соответствие данному протоколу проверяется только при трансляции инстанцированного класса типа UnboundedQueue, в тот момент, когда конкретный класс сопоставляется с формальным аргументом StorageManager.
Объект класса Pool, принадлежащий классу Managed, является статическим. Это позволяет нескольким конкретным структурам (требующим управления) делить между собой единый пул памяти. Различные структуры, не требующие управления, могут, конечно, определить своего менеджера и свой пул памяти, предоставляя таким образом разработчику полный контроль над политикой выделения памяти.
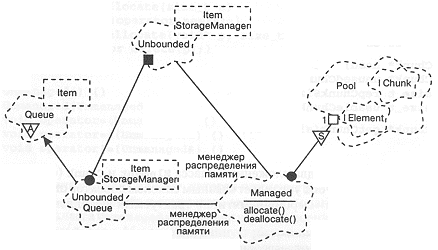 Рис. 9-6. Классы управления памятью.
Рис. 9-6. Классы управления памятью.
На рис. 9-6 приведена диаграмма классов, иллюстрирующая схему взаимодействия различных классов, обеспечивающих управление памятью. Мы показали только ассоциативную связь между классом Managed и его клиентами Unbounded и UnboundedQueue; эта ассоциация будет уточнена при конкретном инстанцировании классов.
Физическая компоновка классов поддержки тоже является частью архитектурного решения. Рис. 9-7 иллюстрирует их модульную архитектуру. Мы выбрали именно такую схему, чтобы изолировать классы, которые, по-видимому, будут чаще всего подвергаться изменениям.
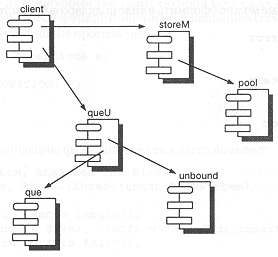 Рис. 9-7. Модули управления памятью.
Рис. 9-7. Модули управления памятью.
Исключения
Несмотря на то, что язык C++ можно заставить соблюдать многие статические предположения (нарушение которых повлечет ошибку компиляции), для выявления динамических нарушений (таких, как попытка добавить элемент к полностью заполненной ограниченной очереди или удалить элемент из пустого списка) приходится использовать и другие механизмы. В данной библиотеке используются средства обработки исключений, предоставляемые C++ [14]. Наша архитектура включает в себя иерархию классов исключений и, отдельно от нее, ряд механизмов по выявлению таких ситуаций.
Начнем с базового класса Exception (исключение), обладающего несложным протоколом:
class Exception {
public:
Exception(const char*
name, const char* who, const char* what);
void display() const;
const char* name() const;
const char* who() const;
const char* what() const;
protected:
...
};
Каждой особой ситуации можно сопоставить имя ее источника и причину
возникновения. Кроме того, мы можем обеспечить скрытые от клиентов средства
для вывода информации об ошибке в соответствующий поток.
Анализ различных классов нашей библиотеки подсказывает возможные типы
исключений, которые можно оформить в виде подклассов базового класса Exception:
-
ContainerError
-
Duplicate
-
IllegalPattern
-
IsNull
-
LexicalError
-
MathError
-
NotFound
-
NotNull
-
NotRoot
-
Overflow
-
RangeError
-
StorageError
-
Underflow
Объявление класса overflow (переполнение) может выглядеть следующим
образом:
class Overflow : public Exception {
public:
Overflow(const char* who, const char* what)
: Exception("Overflow", who, what) {}
};
Обязанность этого класса состоит лишь в знании своего имени, которое он передает конструктору суперкласса.
В данном механизме функции-члены классов библиотеки только возбуждают исключения; они не в состоянии перехватить исключение, главным образом, потому, что ни одна из них не может осмысленно отреагировать на эту ситуацию. По соглашению мы возбуждаем исключение при нарушении условий, предполагавшихся относительно некоторого состояния. Условие представляет собой обычное булевское выражение, которое должно быть истинным в нормальной ситуации. Чтобы упростить библиотеку, мы ввели следующую функцию, не принадлежащую ни одному из классов:
inline void _assert(int expression, const Exception& exception)
{
if (!expression)
throw(exception);
}
Для эффективности мы определили эту функцию как встроенную. Преимущество подобной схемы состоит в том, что она локализует все исключения (в C++ throw имеет синтаксис вызова функции). Так, для трансляторов, которые до сих пор не поддерживают исключений, можно использовать специальную директиву (-D для большинства трансляторов C++) для переопределения вызова throw в вызов другой функции-не-члена, выводящей сообщение на экран и останавливающей выполнение программы:
void _catch(const Exception& e)
{
cerr << "EXCEPTION: ";
e.display();
exit(1);
}
Рассмотрим реализацию функции insert класса Bounded:
template<class Item, unsigned int Size>
void Bounded<Item, Size>::insert(const Item& item)
{
unsigned int count = length();
_assert((count < Size), Overflow("Bounded::Insert", "structure
is full"));
if (!count) start = stop = 1;
else
{
start--;
if (!start) start = Size;
}
rep[start - 1] = item;
}
Предусмотрено, что в процессе выполнения функции проверяется, что размер структуры не превосходит максимально допустимого. Если это не так, возбуждается исключение Overflow.
Важнейшим преимуществом этого подхода является гарантия того, что состояние объекта, возбудившего исключение, не будет нарушено (не считая случая исчерпания оперативной памяти, когда уже в принципе ничего нельзя поделать). Любая функция, прежде чем произвести действия, способные изменить состояние объекта, проверяет предположение. В приведенной выше функции insert, например, прежде, чем добавить элемент в массив, мы сначала вызываем селектор (который не может вызвать изменения состояния объекта), затем проверяем все предусловия функции и лишь затем изменяем состояние объекта. Мы скрупулезно придерживались подобного стиля при реализации всех функций и настоятельно советуем не отходить от него при конструировании подклассов, основанных на нашей библиотеке.
Рис. 9-8 иллюстрирует схему взаимодействия классов, обеспечивающих реализацию механизма обработки исключений.
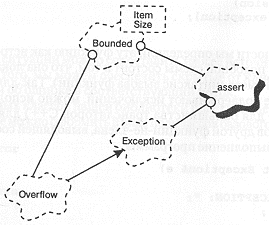 Рис. 9-8. Классы обработки исключений.
Рис. 9-8. Классы обработки исключений.
Итерация
Итерация - это еще один архитектурный шаблон нашей библиотеки. В главе 3 уже отмечалось, что итератор представляет собой операцию, обеспечивающую последовательный доступ ко всем частям объекта. Оказывается, такой механизм нужен не только пользователям, он необходим и при реализации самой библиотеки, в частности, ее базовых классов.
При этом перед нами стоял выбор: можно было определять итерации как часть протокола объектов или создавать отдельные объекты, ответственные за итеративный опрос других структур. Мы выбрали второй подход по двум причинам:
-
Наличие выделенного итератора классов позволяет одновременно проводить несколько просмотров одного и того же объекта.
-
Наличие итерационного механизма в самом классе несколько нарушает его инкапсуляцию; выделение итератора в качестве отдельного механизма поведения способствует достижению большей ясности в описании класса.
Для каждой структуры определены две формы итераций. Активный итератор требует каждый раз от клиента явного обращения к себе для перехода к следующему элементу. Пассивный итератор применяет функцию, предоставляемую клиентом, и, таким образом, требует меньшего участия клиента. Чтобы обеспечить безопасность типов, для каждой структуры создаются свои итераторы.
Рассмотрим в качестве примера активный итератор для класса Queue:
template <class Item>
class QueueActiveIterator {
public:
QueueActiveIterator(const Queue<Item>&);
~QueueActiveIterator();
Пассивный итератор реализует "применяемую" функцию. Эта идиома обычно используется в функциональных языках программирования.
void reset();
int next();
int isDone() const;
const Item* currentItem() const;
protected:
const Queue<Item>& queue;
int index;
};
Каждому итератору в момент создания ставится в соответствие определенный объект. Итерация начинается с "верха" структуры, что бы это ни значило для данной абстракции.
С помощью функции currentItem клиент может получить доступ к текущему элементу; значение возвращаемого указателя может быть нулевым в случае, если итерация завершена или если массив пуст. Переход к следующему элементу последовательности происходит после вызова функции next (которая возвращает 0, если дальнейшее движение невозможно, как правило, из-за того, что итерация завершена). Селектор isDone служит для получения информации о состоянии процесса: он возвращает 0, если итерация завершена или структура пуста. Функция reset позволяет осуществлять неограниченное количество итерационных проходов по объекту.
Например, при наличии следующего объявления:
BoundedQueue<NetworkEvent> eventQueue;
фрагмент кода, использующий активный итератор для захода в каждый элемент очереди, будет выглядеть так:
QueueActiveIterator<NetworkEvent> iter(eventQueue);
while (!iter.isDone()) {
iter.currentItem()->dispatch();
iter.next();
}
Итерационная схема, приведенная на рис. 9-9, иллюстрирует данный сценарий работы и, кроме того, раскрывает некоторые детали реализации итератора. Рассмотрим их более подробно.
Конструктор класса QueueActiveIterator сначала устанавливает связь между итератором и конкретной очередью. Затем он вызывает защищенную функцию cardinality, которая определяет количество элементов в очереди. Таким образом, конструктор можно описать следующим образом:
template<class Item>
QueueActiveIterator<Item>::QueueActiveIterator(const Queue<Item>&
q)
:queue(q), index(q.cardinality() ? 0 : -1) {}
Класс QueueActiveIterator имеет доступ к защищенной функции cardinality класса Queue, поскольку числится в дружественных ему.
Операция итератора isDone проверяет принадлежность текущего индекса допустимому диапазону, который определяется количеством элементов очереди:
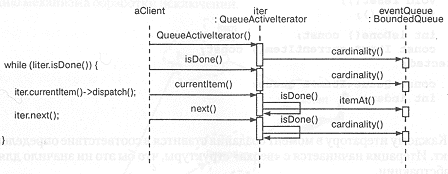 Рис. 9-9. Механизм итерации.
Рис. 9-9. Механизм итерации.
template<class Item>
int QueueActiveIterator<Item>::isDone() const
{
return ((index < 0) || (index >= queue.cardinality()));
}
Функция currentItem возвращает указатель на элемент, на котором остановился итератор. Реализация итератора в виде индекса объекта в очереди дает возможность в процессе итераций без труда добавлять и удалять элементы из очереди:
template<class Item>
const Item* QueueActiveIterator<Item>::currentItem() const
{
return isDone() ? 0 : &queue.itemAt(index);
}
При выполнении данной операции итератор снова вызывает защищенную функцию очереди, на сей раз itemAt. Кстати, currentItem можно использовать для работы как с ограниченной, так и с неограниченной очередью. Для ограниченной очереди itemAt просто возвращает элемент массива по соответствующему индексу. Для неограниченной очереди операция itemAt будет осуществлять проход по связному списку. Правда, как мы помним, класс Unbounded хранит информацию о последнем элементе, к которому было обращение, поэтому переход к следующему за ним элементу очереди (что и происходит при продвижении итератора) будет достаточно простым.
Операция next увеличивает значение текущего индекса на единицу, что соответствует переходу к следующему элементу очереди, а затем проверяет допустимость нового значения индекса:
template<class Item>
int QueueActiveIterator<Item>::next()
{
index++;
return !isDone();
}
Итератор, таким образом, в процессе своей работы вызывает две защищенные функции класса Queue: cardinality и itemAt. Определив эти функции как чисто виртуальные, мы передали ответственность за их конкретную оптимальную реализацию классам, производным от Queue.
Ранее отмечалось, что одна из основных задач наших архитектурных решений заключается в том, чтобы дать возможность клиенту копировать, присваивать и проверять на равенство экземпляры абстрактного базового класса, даже если они имеют различное представление. Эта возможность достигается за счет использования итераторов и некоторых служебных функций, позволяющих просматривать структуры независимо от их представления. Например, оператор присваивания для класса Queue можно определить следующим образом:
template<class Item>
Queue<Item>& Queue<Item>::operator=(const Queue<Item>&
q)
{
if (this == &q) return *this;
((Queue<Item>&)q).lock();
purge();
QueueActiveIterator<Itea> iter(q);
while (!iter.isDone()) {
add(*iter.currentItem());
iter.next();
}
((Queue<Item>&)q).unlock();
return *this;
}
В данном алгоритме используется идиома блокирования, которая более подробно рассмотрена в следующем разделе.
Присваивание осуществляется в порядке просмотра активным итератором структуры, определяемой аргументом q. Сначала защищенная служебная функция purge очищает очередь, а затем к ней с помощью другой защищенной служебной функции add последовательно добавляются новые элементы. Тот факт, что процесс итерации осуществляется с помощью полиморфных функций, дает возможность копировать, присваивать и проверять на равенство объекты, имеющие одинаковую структуру, но с разными представлениями.
Пассивный итератор, который также называют аппликатором, характеризуется тем, что он применяет определенную функцию к каждому элементу структуры. Для класса Queue пассивный итератор можно определить следующим образом:
template <class Item>
class QueuePassiveIterator {
public:
QueuePassiveIterator(const Queue<Item>&);
~QueuePassiveIterator();
int apply(int (*)(const Item&));
protected:
const Queue<Item>& queue;
};
Пассивный итератор действует на все элементы структуры за (логически) одну операцию. Таким образом, функция apply последовательно производит одну и ту же операцию над каждым элементом структуры, пока передаваемая итератору функция не возвратит нулевое значение или пока не будет достигнут конец структуры (в первом случае функция apply сама возвратит нулевое значение в знак того, что итерация не была завершена).
Синхронизация
При разработке любого универсального инструментального средства должны учитываться проблемы, связанные с организацией параллельных процессов. В операционных системах типа UNIX, OS/2 и Windows NT приложения могут запускать несколько "легких" процессов ["Легким" называется процесс, который исполняется в том же адресном пространстве, что и другие. В противоположность им существуют "тяжелые" процессы; их создает, например, функция fork в UNIX. Тяжелые процессы требуют специальной поддержки операционной системы для организации связи между собой. Для C++ библиотека AT&T предлагает "полупереносимую" абстракцию легких процессов для UNIX. Легкие процессы непосредственно доступны в OS/2 и Windows NT. В библиотеку классов Smalltalk включен класс Process, реализующий поддержку легких процессов]. В большинстве случаев классы просто не смогут работать в такой среде без специальной доработки: когда две задачи взаимодействуют с одним и тем же объектом, они должны делать это согласованно, чтобы не разрушить состояния объекта. Как уже отмечалось, существуют два подхода к задаче управления процессами; они находят свое отражение в существовании защищенной и синхронизированной форм класса.
При разработке данной библиотеки было сделано следующее предположение: разработчики, планирующие использовать параллельные процессы, должны импортировать либо разработать сами по крайней мере класс Semaphore (семафор) для синхронизации легких процессов. Разработчики, которые не хотят связываться с параллельными процессами, будут свободны от необходимости поддерживать защищенные или синхронизованные формы классов (таким образом, не потребуется никаких дополнительных издержек). Защищенные и синхронизированные формы изолированы в библиотеке и основываются на своей внутренней реализации параллелизма. Единственная зависимость от локальной реализации сосредоточена в классе Semaphore, который имеет следующий интерфейс:
class Semaphore {
public:
Semaphore();
Semaphore(const Semaphore&);
Semaphore(unsigned int count);
~Semaphore();
void seize(); // захватить
void release(); // освободить
unsigned int nonePending() const;
protected:
};
Так же, как и при управлении памятью, мы разделяем политику синхронизации процессов и ее реализацию. По этой причине в аргументы шаблона для каждой защищенной формы включен класс Guard (страж), ответственный за связь с локальной реализацией класса Semaphore или его эквивалента. Аргументы шаблона для каждой из синхронизированных форм содержат класс Monitor, который близок по своим функциональным свойствам к классу Semaphore, но, как будет видно в дальнейшем, обеспечивает более высокий уровень параллелизма процессов.
Как показано на рис. 9-3, защищенный класс является прямым подклассом
своего конкретного ограниченного либо неограниченного класса и содержит
в себе объект класса Guard. Все защищенные классы имеют общедоступные
функции-члены seize (захватить) и release (освободить), позволяющие
получить эксклюзивный доступ к объекту. Рассмотрим в качестве примера класс
GuardedUnboundedQueue, производный от UnboundedQueue:
template<class Item, class StorageManager, class Guard>
class GuardedUnboundedQueue : public UnboundedQueue<Item,
StorageManager> {
public:
GuardedUnboundedQueue();
virtual ~GuardedUnboundedQueue();
virtual void seize();
virtual void release();
protected:
Guard guard;
};
В нашей библиотеке предусмотрен интерфейс одного из предопределенных
классов защиты: класса semaphore. Пользователи могут дополнить реализацию
данного класса в соответствии с локальным определением легкого процесса.
На рис. 9-10 приведена схема работы данного варианта синхронизации; клиенты, использующие защищенные объекты, должны придерживаться простого алгоритма: сначала захватить объект для эксклюзивного доступа, провести над ним нужную работу, и после ее окончания снять защиту (в том числе в тех случаях, когда возникла исключительная ситуация). Другая схема поведения рассматривается как социально неприемлемая, поскольку претензии одного агента не позволят правильно работать другим. Если мы, например, не снимем защиту после окончания работы с объектом, больше никто не сможет получить к нему доступ; попытка снятия защиты с объекта, к которому в данный момент никто не имел эксклюзивного доступа, также может привести к нежелательным последствиям. Игнорирование этого протокола просто безответственно, поскольку оно может разрушить состояние объекта, с которым одновременно работают несколько агентов.
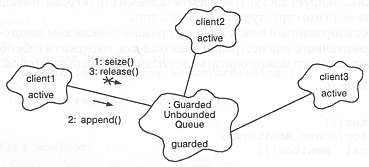 Рис. 9-10. Процессы защищенного механизма.
Рис. 9-10. Процессы защищенного механизма.
Основное преимущество защищенной схемы - ее простота. В то же время для агентов, производящих операции над одним и тем же объектом, использование данной модели обуславливает необходимость выполнения определенных коллективных действий. Другая особенность защищенных форм состоит в том, что она дает возможность агентам выделять критически важные моменты, когда несколько операций, произведенных над объектом, будут гарантированно интерпретироваться как одна атомарная транзакция.
Подобно механизму управления памятью, сигнатура шаблона защищенной формы импортирует стража, а не превращает его в неизменяемую характеристику. Это позволяет пользователям ввести новую политику синхронизации. При использовании в качестве стража предопределенного класса Semaphore, стандартная политика синхронизации подразумевает, что каждому объекту ставится в соответствие свой семафор. Данное решение приемлемо только до тех пор, пока количество параллельных процессов не достигнет некоторого критического значения.
Альтернативный подход подразумевает возможность обслуживания одним семафором сразу нескольких защищенных объектов. Разработчику при этом нужно только создать новый класс-страж, имеющий тот же протокол, что и semaphore (но не обязательно являющийся его подклассом). Этот класс может содержать семафор в качестве статического члена; тогда семафор будет совместно использоваться всеми экземплярами класса. Инстанцируя защищенную форму с этим новым стражем, разработчик библиотеки вводит новую политику, поскольку все объекты инстанцированного класса пользуются общим стражем, вместо выделения отдельного стража каждому объекту. Преимущество данной схемы наиболее ясно проявляется, когда новый класс-страж используется для инстанцирования других структур: все полученные объекты будут работать с одним и тем же стражем. Таким образом, на первый взгляд незначительное изменение политики приводит не только к уменьшению количества параллельных процессов, но также позволяет клиенту блокировать целую группу объектов, несвязанных напрямую. Захват одного объекта автоматически блокирует доступ и ко всем остальным структурам, имеющим того же стража, даже если это структуры различного типа.
Синхронизированный класс, являясь прямым подклассом какого-либо конкретного
ограниченного или неограниченного класса, содержит в себе объект-монитор,
протокол которого можно описать следующим абстрактным базовым классом:
class Monitor {
public:
Monitor();
Monitor(const Monitor&);
virtual ~Monitor();
virtual void seizeForReading() = 0;
virtual void seizeForWriting() = 0;
virtual void releaseFromBeadingt() = 0;
virtual void releaseFromWritingt() = 0;
protected:
...
};
С помощью мониторов можно реализовать два типа синхронизации:
| ® Одиночная |
Гарантирует семантику структуры в присутствии нескольких потоков управления, но с одним читающим или одним записывающим. |
| ® Множественная |
Гарантирует семантику структуры в присутствии нескольких потоков управления,
с несколькими читающими или одним записывающим. |
Агент записи меняет состояние объекта; агенты записи вызывают функции-модификаторы. Агент чтения сохраняет состояние объекта; он вызывает только функции-селекторы. Как видно, множественная форма синхронизации обеспечивает наивысшую степень параллелизма процессов. Мы можем реализовать обе политики в виде подклассов абстрактного базового класса Monitor. Обе формы можно построить на основе класса Semaphore.
В отличие от защищенных форм, синхронизованные классы не содержат дополнительных функций-членов по сравнению со своим суперклассом: они просто переопределяют все виртуальные функции суперкласса. Семантика, вносимая синхронизированным классом, заставляет трактовать каждую такую функцию как атомарную транзакцию. В то время, как клиенты защищенного объекта должны для получения эксклюзивного доступа каждый раз явно захватывать и освобождать доступ, синхронизированные формы обеспечивают эксклюзивность доступа, не требуя специальных действий со стороны своих клиентов.
Это достигается с помощью механизма блокировки, схема работы которого
приведена на рис. 9-11. Взаимодействие мониторов с экземплярами предопределенных
классов ReadLock и WriteLock обеспечивает эксклюзивность
вызова каждой функции-члена. В этом механизме блокировка использует либо
семафор, либо монитор в качестве агента, ответственного за процесс синхронизации,
а сама блокировка отвечает за захват этого агента при создании и освобождение
при удалении. В качестве примера рассмотрим определение класса ReadLock:
class ReadLock {
public:
ReadLock (const Monitor& m) : monitor(m)
{ monitor.seizeForReading(); }
~ReadLock() { monitor.releaseFromReading();
}
private:
Monitor& monitor;
};
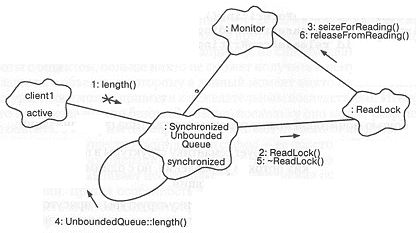 Рис. 9-11. Механизм блокировки.
Рис. 9-11. Механизм блокировки.
Определив блокировку и ее монитор как две отдельные абстракции, мы дали клиенту возможность использовать различные политики блокировки. Описание класса WriteLock аналогично, разница лишь в том, что он использует протокол монитора для записи.
Описания всех функций-членов синхронизированного класса используют блокировки для "оборачивания" операций, унаследованных из суперкласса. Рассмотрим в качестве примера реализацию функции length для синхронизированной неограниченной очереди:
template<class Item, class StorageManager, class Monitor>
unsigned int SynchronizedUnboundedQueue<Item, StorageManager,
Monitor>::length() const
{
ReadLock lock(monitor);
return UnboundedQueue<Item, StorageManager>::length();
}
Данный фрагмент кода иллюстрирует механизм, приведенный на рис. 9-11. Как правило, объекты класса ReadLock используются для всех синхронизированных селекторов, а экземпляры WriteLock - для синхронизированных модификаторов. Простота и элегантность подобной архитектуры проявляется в том, что каждая функция представляет собой законченную операцию, в любом случае гарантирующую сохранность состояния объекта, причем без каких-либо явных действий со стороны агентов чтения/записи.
Действительно, клиенты, работающие с синхронизированными объектами, не должны придерживаться специальной последовательности действий, так как механизм синхронизации процессов поддерживается здесь в неявном виде. Это исключает появление ошибок типа неверной блокировки. Разработчику следует, однако, предпочитать защищенную форму синхронизированной, когда вызов нескольких функций нужно оформить как атомарную транзакцию; синхронизированная форма может гарантировать атомарность только отдельных функций-членов.
Наша архитектура обеспечивает синхронизированным формам отсутствие ситуаций типа "смертельное объятие". Например, операции присваивания объекта самому себе или сравнения его с самим собой потенциально опасны, так как требуют блокировки и левого и правого элементов выражения, которые в данном случае являются одним и тем же объектом. Будучи создан, объект не может изменить свою идентичность, поэтому тесты на самоидентичность выполнятся до блокировки какого-либо объекта. Именно поэтому описанный ранее оператор присваивания operator= включал такую проверку, как показывает следующая сокращенная запись:
template<class Item>
Queue<Item>& Queue<Item>::operator=(const Queue<Item>&
q)
{
if (this == &q) return *this;
}
Любые функции-члены, среди аргументов которых есть экземпляры класса, к которому они принадлежат, должны проектироваться так, чтобы обеспечивалась корректная схема блокировки этих аргументов. Наше решение базируется на полиморфизме двух служебных функций, lock и unlock, определенных в каждом абстрактном базовом классе. Каждый абстрактный базовый класс по умолчанию содержит заглушку для этих двух функций; синхронизированные формы обеспечивают захват и освобождение аргумента. Вот почему описанный ранее оператор присваивания operator= включал вызовы этих двух функций, как показывает следующая сокращенная запись:
template<class Item>
Queue<Item>& Queue<Item>::operator=(const Queue<Item>&
q)
{
((Queue<Item>&)q).lock();
((Queue<Item>&)q).unlock();
return *this;
}
Явное приведение типа используется в данном случае для того, чтобы освободиться от ограничения const на аргумент.
9.3. Эволюция
Проектирование интерфейса классов
После того, как выработаны основные принципы построения архитектуры системы, остающаяся работа проста, но зачастую довольно скучна и утомительна. Следующий этап будет состоять в реализации трех или четырех семейств классов (таких, как очередь, множество и дерево) в соответствии с выбранной архитектурой, и в последующем их тестировании в нескольких приложениях [Вирфс-Брок считает, что необходимо тестировать среду разработки по крайней мере на трех приложениях, чтобы проверить правильность стратегических и тактических решений [15]].
Наиболее тяжелой частью данного этапа является создание подходящего интерфейса для каждого базового класса. И здесь, в процессе изолированной разработки отдельных классов (см. главу 6), нельзя забывать о задаче обеспечения глобального соответствия всех частей системы друг другу. В частности, для класса Set можно определить следующий протокол:
| ® setHashFunction |
Устанавливает функцию хеширования для элементов множества. |
| ® clear |
Очищает множество. |
| ® add |
Добавляет элемент к множеству. |
| ® remove |
Удаляет элемент из множества. |
| ® setUnion |
Объединяет с другим множеством. |
| ® intersection |
Находит пересечение с другим множеством. |
| ® difference |
Удаляет элементы, которые содержатся в другом множестве. |
| ® extent |
Возвращает количество элементов в множестве. |
| ® isEmpty |
Возвращает 1, если множество пусто. |
| ® isMember |
Возвращает 1, если данный элемент принадлежит множеству. |
| ® isSubset |
Возвращает 1, если множество является подмножеством другого множества. |
| ® isProperSubset |
Возвращает 1, если множество является собственным подмножеством другого
множества. |
Подобным же образом можно определить протокол класса BinaryTree:
| ® clear |
Уничтожает дерево и всех его потомков. |
| ® insert |
Добавляет новый узел в корень дерева. |
| ® append |
Добавляет к дереву потомка. |
| ® remove |
Удаляет потомка из дерева. |
| ® share |
Структурно делит данное дерево. |
| ® swapChild |
Переставляет потомка с деревом. |
| ® child |
Возвращает данного потомка. |
| ® leftChild |
Возвращает левого потомка. |
| ® rightChild |
Возвращает правого потомка. |
| ® parent |
Возвращает родителя дерева. |
| ® setItem |
Устанавливает элемент, ассоциированный с деревом. |
| ® hasChildren |
Возвращает 1, если у дерева есть потомки. |
| ® isNull |
Возвращает 1, если дерево нулевое. |
| ® isShared |
Возвращает 1, если дерево структурно разделено. |
| ® isRoot |
Возвращает 1, если дерево имеет корень. |
| ® itemAt |
Возвращает элемент, ассоциированный с деревом. |
Для схожих операций мы используем схожие имена. При разработке интерфейса мы также проверяем полученное решение на соответствие критериям достаточности, полноты и примитивности (см. главу 3).
Классы поддержки
При реализации класса, ответственного за манипуляции с текстовыми строками, мы столкнулись с тем, что возможностей, предоставляемых классами поддержки Bounded и Unbounded, явно недостаточно. Ограниченная форма, в частности, оказывается неэффективной для работы со строками с точки зрения памяти, так как мы должны инстанцировать эту форму в расчете на максимально возможную строку, и следовательно понапрасну расходовать память на более коротких строках. Неограниченная форма, в свою очередь, неэффективна с точки зрения быстродействия: поиск элемента в строке может потребовать последовательного перебора всех элементов связного списка. По этим причинам нам пришлось разработать третий, "динамический" вариант:
| ® Динамический |
Структура хранится в "куче" в виде массива, длина которого может уменьшаться или увеличиваться. |
Структура хранится в "куче" в виде массива, длина которого может уменьшаться или увеличиваться.
Соответствующий класс поддержки Dynamic представляет собой промежуточный вариант по отношению к ограниченному и неограниченному классам, обеспечивающий быстродействие ограниченной формы (возможно прямое индексирование элементов) и эффективность хранения данных, присущую неограниченной форме (память выделяется только под реально существующие элементы).
Ввиду того, что протокол данного класса идентичен протоколу классов Bounded и Unbounded, добавление к библиотеке нового механизма не составит большого труда. Мы должны создать по три новых класса для каждого семейства (например, DynamicString, GuardedDynamicString и SynchronizedDynamicString). Таким образом, мы вводим следующий класс поддержки:
template<class Item, class StorageManager>
class Dynamic {
public:
Dynamic(unsigned int chunkSize);
protected:
Item* rep;
unsigned int size;
unsigned int totalChunks;
unsigned int chunkSize;
unsigned int start;
unsigned int stop;
void resize(unsigned int currentLength,
unsigned int newLength, int preserve - 1);
unsigned int expandLeft(unsigned int from);
unsigned int expandRight(unsigned int from);
void shrinkLeft(unsigned int from);
void shrinkRight(unsigned int from);
};
Последовательности разбиваются на блоки в соответствии с аргументом
конструктора chunkSize. Таким образом, клиент может регулировать
размер будущего объекта.
Из интерфейса видно, что класс Dynamic имеет много общего с классами
Bounded и Unbounded. Отличия в реализации трех типов классов
каждого семейства будут минимальны.
Займемся теперь классом ассоциативных массивов. Его реализация потребует
новой переработки ограниченной, динамической и неограниченной форм. В частности,
поиск элемента в ассоциативном массиве требует слишком много времени, если
его приходится вести перебором всех элементов. Но производительность можно
значительно увеличить, используя открытые хеш-таблицы.
Абстракция открытой хеш-таблицы проста. Таблица представляет собой массив
последовательностей, которые называются клетками. Помещая в таблицу новый
элемент, мы сначала генерируем хеш-код по этому элементу, а затем используем
код для выбора клетки, куда будет помещен элемент. Таким образом, открытая
хеш-таблица делит длинную последовательность на несколько более коротких,
что значительно ускоряет поиск.
Соответствующую абстракцию можно определить следующим образом:
template<class Item, class Value, unsigned int Buckets, class
Container>
class Table {
public:
Table(unsigned int (*hash)(const Item&));
void setHashFunction(unsigned int (*hash)(const Item&));
void clear();
int bind(const Item&, const Value&);
int rebind(const Item&, const Value&);
int unbind(const Item&);
Container* bucket(unsigned int bucket);
unsigned int extent() const;
int isBound(const Item&) const;
const Value* valueOf(const Item&) const;
const Container *const bucket(unsigned int bucket) const;
protected:
Container rep[Buckets];
};
Использование класса Container в качестве аргумента шаблона позволяет применить абстракцию хеш-таблицы вне зависимости от типа конкретной последовательности. Рассмотрим в качестве примера (сильно упрощенное) объявление неограниченного ассоциативного массива, построенного на базе классов Table и Unbounded:
template<class Item, class Value, unsigned int Buckets,
class StorageManager>
class UnboundedMap : public Map<Item, Value> {
public:
UnboundedMap();
virtual int bind(const Item&, const Value&);
virtual int rebind(const Item&, const Value&);
virtual int unbind(const Item&);
protected:
Table<Item, Value, Buckets, Unbounded<Pair<Item,
Value>, StorageManager>> rep;
};
В данном случае мы истанцируем класс Table контейнером unbounded. Рис. 9-12 иллюстрирует схему взаимодействия этих классов.
В качестве свидетельства общей применимости этой абстракции мы можем использовать класс Table при реализации классов множеств и наборов.
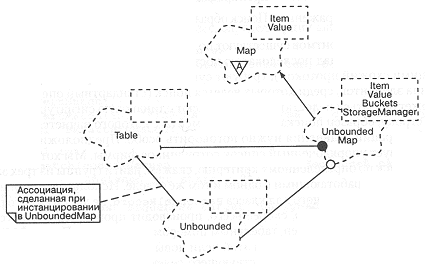 Рис. 9-12. Классы поддержки.
Рис. 9-12. Классы поддержки.
Инструменты
Для нашей библиотеки основная роль шаблонов заключается в параметризации структур типами элементов, которые будут в них содержаться; поэтому такие структуры называют классами-контейнерами. Но, как видно из определения класса Table, шаблоны можно использовать также для передачи классу некоторой информации о реализации.
Еще более сложная ситуация возникает при создании инструментов, которые оперируют с другими структурами. Как уже отмечалось, алгоритмы тоже можно представить в виде классов, объекты которых будут выступать в роли агентов, ответственных за выполнение алгоритма. Такой подход соответствует идее Джекобсона об объекте управления, который служит связующим звеном, осуществляющим взаимодействие обычных объектов [16]. Преимущество данного подхода состоит в возможности создания семейств алгоритмов, объединенных наследованием. Это не только упрощает их использование, но также позволяет объединить концептуально схожие алгоритмы.
Рассмотрим в качестве примера алгоритмы поиска образца внутри последовательности. Существует целый ряд подобных алгоритмов:
| ® Простой |
Поиск образца последовательной проверкой всей структуры. В худшем случае временной показатель сложности данного алгоритма будет O(pn), где p - длина образца и n - длина последовательности. |
| ® Кнут-Моррис-Пратт |
Поиск образца с временным показателем O(p+n) (Knuth-Morris-Pratt). Алгоритм не требует создания копий, поэтому годится для поиска в потоках. |
| ® Бойер-Мур |
Поиск с сублинейным временным показателем (Boyere-Moore) O(c(p+n)), где c меньше 1 и обратно пропорционально p. |
| ® Регулярное выражение |
Поиск образца, заданного регулярным выражением. |
У всех этих алгоритмов существуют по крайней мере три общие черты: все они проводят операции над последовательностями (и значит работают с объектами, имеющими схожий протокол), требуют существования операции сравнения для того типа элементов, среди которых ведется поиск (стандартный оператор сравнения может оказаться недостаточным), и имеют одинаковую сигнатуру вызова (целевую строку, образец поиска и индекс элемента, с которого начнется поиск).
Об операции сравнения нужно поговорить особо. Предположим, например, что существует упорядоченный список сотрудников фирмы. Мы хотим произвести в нем поиск по определенному критерию, скажем, найти группы из трех записей с сотрудниками, работающими в одном и том же отделе. Использование оператора operator==, определенного для класса PersonnelRecord, не даст нужного результата, так как этот оператор, скорее всего, производит проверку в соответствии с другим критерием, например, табельным номером сотрудника. Поэтому нам придется специально разработать для этой цели новый оператор сравнения, который запрашивал бы (вызовом соответствующего селектора) название отдела, в котором работает сотрудник. Поскольку каждый агент, выполняющий поиск по образцу, требует своей функции проверки на равенство, мы можем разработать общий протокол введения такой функции в качестве части некоторого абстрактного базового класса. Рассмотрим в качестве примера следующее объявление:
template<class Item, class Sequence>
class PatternMatch {
public:
PatternMatch();
PatternMatch(int (*isEqual)(const Item& x, const Item&
y));
virtual ~PatternMatch();
virtual void setIsEqualFunction(int (*)(const Item& x, const
Item& y));
virtual int match(const Sequence& target, const Sequences;
pattern, unsigned int start = 0) = 0;
virtual int match(const Sequence&; target, unsigned
int start = 0) = 0;
protected:
Sequence rep;
int (*isEqual)(const Item& x, const Item& y);
private:
void operator=(coust PattemMatcb&) {}
void operator==(const PatternMatch&) {}
void operator!=(const PatternMatch&) {}
};
Операции присваивания и сравнения на равенство для объектов данного
класса и его подклассов невозможны, поскольку мы использовали соответствующие
идиомы. Мы сделали это, потому что операции присваивания и сравнения не
имеют смысла для абстракций агентов.
Теперь опишем конкретный подкласс, определяющий алгоритм Бойера-Мура:
template<class Item, class Sequence>
class BMPatternMatch : public PatternMatch<Item, Sequence>
{
public:
BMPatternMatch();
BMPattemMatch(int (*isEqual) (const Item& x, const Item&
y));
virtual ~BMPattemMatch();
virtual int match(const Sequence& target, const Seque
unsigned int start = 0);
virtual int match(const Sequence& target, unsigned
in
protected:
unsigned int length;
unsigned int* skipTable;
void preprogress(const Sequence& pattern);
unsigned int itemsSkip(const Sequence& pattern, const Item&
item);
};
 Рис. 9-13. Классы поиска.
Рис. 9-13. Классы поиска.
Открытый протокол этого класса полностью копирует соответствующий протокол своего суперкласса. Кроме того, его описание дополнительно включает два элемента данных и две вспомогательные функции. Одна из особенностей данного класса состоит в создании временной таблицы, которая используется для пропуска длинных неподходящих последовательностей. Эти добавочные элементы нужны для реализации алгоритма.
На рис. 9-13 приведена иерархия классов поиска. Иерархия подобного типа применима для большинства инструментов библиотеки. При этом формируются сходные по структуре семейства классов, что позволяет пользователям легко в них ориентироваться и выбирать те, которые наилучшим образом подходят для их приложений.
9.4. Сопровождение
Одно из наиболее интересных свойств сред разработки заключается в том, что, в случае удачной реализации, они стремятся набрать некую критическую массу функциональности и адаптируемости. Другими словами, если мы правильно выбрали основные абстракции и наделили библиотеку рядом хорошо взаимодействующих между собой механизмов, то вскоре обнаружим, что клиенты используют наш продукт для решения тех задач, о которых разработчики среды и не подозревали. После того, как определились основные схемы использования среды, имеет смысл сделать их формальной частью самой библиотеки. Признаком правильности конструкции среды разработки является возможность внедрения новых моделей поведения с помощью повторного использования уже существующих свойств продукта и без нарушения принципов его архитектуры.
Одной из таких задач является проблема времени жизни объектов. Может встретиться клиент, который не хочет или не нуждается в использовании полно масштабной объектно-ориентированной базы данных, а планирует лишь время от времени сохранять состояние таких структур, как очереди и множества, чтобы иметь возможность получить их состояние при следующем вызове из той же программы или из другого приложения. Принимая во внимание то, что подобные требования могут возникать довольно часто, имеет смысл дополнить нашу библиотеку простым механизмом сохранения объектов.
Сделаем два допущения, касающихся этого механизма. Во-первых, клиент должен обеспечить потоки, в которые объекты будут записываться и считываться. Во-вторых, клиент обязан обеспечить объектам поведение, необходимое для направления в поток.
Для создания такого механизма есть два альтернативных подхода. Можно построить класс-примесь, обеспечивающий семантику "долгожития"; именно такой подход реализован во многих объектно-ориентированных базах данных. В качестве альтернативы можно создать класс, экземпляры которого выступают в качестве агентов, ответственных за перенаправление различных структур в поток. Для того, чтобы обосновать наш выбор, попробуем оценить преимущества и недостатки того и другого подхода.
Как оказалось, для выбранного очень простого механизма сохраняемости примесь не совсем подходит (зато она очень хорошо вписывается в архитектуру настоящей объектно-ориентированной базы данных). При использовании примеси пользователь должен сам добавить ее к своему классу, зачастую переопределив при этом некоторые служебные функции класса-примеси. В нашем случае, для такого простого механизма это окажется неэффективным, так как пользователю будет легче разработать свои средства, чем дорабатывать библиотечные. Таким образом, мы склоняемся ко второму решению, которое потребует от пользователя лишь создания экземпляра уже существующего класса.
Рис. 9-14 иллюстрирует работу такого механизма, продлевающего жизнь объектов за счет работы отдельного агента. Класс Persist является дружественным классу Queue; мы определяем эту связь внутри описания класса Queue следующим образом:
friend class Persist<Item, Queue<Item>>;
В этом случае классы становятся дружественными только в момент инстан-цирования класса Queue. Внедрив подобные описания дружественности в каждый абстрактный базовый класс, мы обеспечиваем возможность использования Persist с любой структурой библиотеки.
Параметризованный класс Persist содержит операции записи и считывания put и get, а также функции для подключения потоков обмена данными. Мы можем определить данную абстракцию следующим образом:
template<class Item, class Structure>
class Persist {
public:
Persist();
Persist(iostream& input, iostream& output);
virtual ~Persist();
virtual void setInputStream(iostream&);
virtual void setOutputStream(iostream&);
virtual void put(Structure&);
virtual void get(Structure&);
protected:
iostream* inStreain;
iostream* outStream;
};
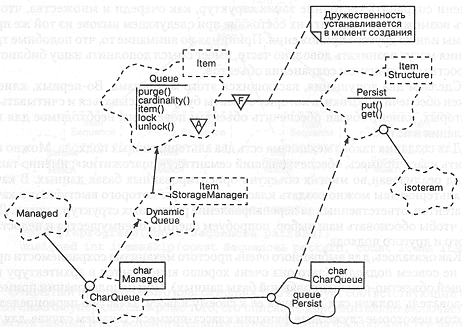 Рис. 9-14. Обеспечение сохраняемости с помощью агента.
Рис. 9-14. Обеспечение сохраняемости с помощью агента.
Реализация данного класса зависит от того, является ли он дружественным классу Structure, который фигурирует в качестве аргумента шаблона. В частности, Persist зависит от наличия в структуре вспомогательных функций purge, cardinality, itemAt, lock, и unlock. Далее срабатывает однородность нашей библиотеки: поскольку каждый базовый класс Structure имеет подобные функции, то persist можно безо всяких изменений использовать для работы со всеми имеющимися в библиотеке структурами.
Рассмотрим в качестве примера реализацию функции Persist::put:
template<class Item, class Structure>
void Persist<Item, Structure>::put(Structure& s)
{
s.lock();
unsigned int count = s.cardinality();
(*outStream) << count << endl;
for (unsigned int index = 0; index < count; index++)
(*outStream) << s.itemAt(index);
s.unlock();
}
Эта операция использует разработанный нами ранее механизм блокировки, поэтому она будет работать и для защищенных, и для синхронизированных форм. Алгоритм работы функции несложен: сначала в поток выводится количество элементов структуры, а затем, последовательно, все ее элементы. Реализация persist::get аналогично выполняет обратное действие:
template<class Item, class Structure>
void Persist<Item, Structure>::get(Structure& s)
{
s.lock();
unsigned int count;
Item item;
if (! inStream->eof()) {
(*inStream) >> count;
s.purge();
for (unsigned int index = 0; (index < count) && (!
inStream->eof());
index++)
{
(*inStream) >> item;
s.add(item);
}
}
s.unlock();
}
Для того, чтобы использовать этот простой механизм сохранения данных, клиенту надо всего лишь инстанцировать один дополнительный класс для каждой
структуры.
Задача построения среды разработки является довольно сложной. При конструировании основных иерархий классов необходимо учитывать различные, зачастую противоречивые требования к системе. Старайтесь сделать вашу библиотеку как можно более гибкой: никогда нельзя предсказать, как именно попытается ее использовать разработчик. Также очень важно сделать ее как можно более независимой от программной среды - так легче будет использовать ее совместно с другими библиотеками. Предлагаемые абстракции должны быть как можно более простыми, эффективными и понятными разработчику. Самые элегантные решения никогда не будут использованы, если сроки их освоения превысят время, необходимое программисту для решения проблемы своими силами. Сказать, что эффект достигнут, можно будет только когда станет видно, что ваши абстракции используются повторно много раз. То есть, когда разработчик ощутил преимущества их использования и не изобретает велосипед, а сосредоточивает внимание на тех особенностях задачи, которые еще никем не были решены.
Дополнительная литература
Бигерстафф и Перлис (Biggerstaffand Perlis) [H 1989] провели исчерпывающий анализ повторного использования программного обеспечения. Вирфс-Брок (Wirfs-Brock) [С 1988] предложил хорошее введение в объектно-ориентированные среды разработки. Джонсон (Johnson) [G 1992] изучал вопросы документирования архитектуры сред разработки и выявил ряд общих моментов.
Библиотека МасАрр [G 1989] для Macintosh является хорошим примером правильно сконструированной объектно-ориентированной прикладной среды разработки. Введение в более раннюю версию этой библиотеки классов может быть найдено у Шмукера (Schmucker) [G 1986]. В недавней работе Голдстейн и Алджер (Goldstein and Alger) [С 1992] обсуждают развитие объектно-ориентированного программного обеспечения для Macintosh.
Другие примеры сред разработки: гипермедиа (Мейровиц (Meirowitz) [С 1986]), распознавание образов (Йошида (Yoshida) [С 1988]), интерактивная графика (Янг (Young) [С 1987]), настольные издательские системы (Феррел (Ferrel) [K 1989]). Среды разработки общего назначения: ЕТ++ (Вейнанд (Weinand) [K 1989]) и управляемые событиями MVC-архитектуры (Шэн (Shan) [G 1989]). Коггинс (Coggins) [С 1990] изучил, в частности, развитие библиотек для C++.
Эмпирическое изучение объектно-ориентированных архитектур и их влияния на повторное использование можно найти в работе Льюиса (Lewis) [С 1992].
|

